Carpe Diem
Similar Threads
What is A book vs B book in Forex trading? 30 replies
A book forex brokers VS B book brokers, differences? 12 replies
Traders' Book Club 10 replies
The Book Club 5 replies
 The Finance Book Club
The Finance Book Club
- #62
- Edited 2:23am Jul 30, 2020 2:06am | Edited 2:23am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Evidence-Based Technical Analysis Chapter 5 (part two)
Computer-Intensive Methods for Generating The Sampling Distribution 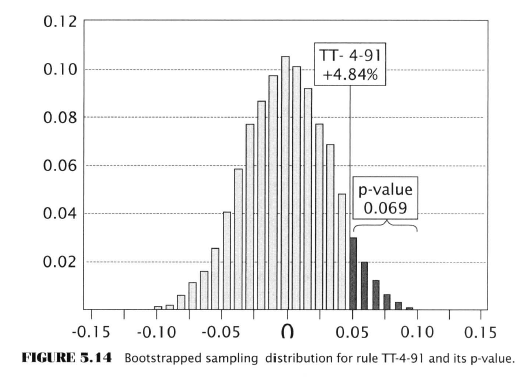
Computer-Intensive Methods for Generating The Sampling Distribution
- Hypothesis-testing needs a method for estimating the shape of the sampling distribution of the test statistic
- Traditional method - (classical) - Fisher & Neyman, etc.
- Computer - based - randomly resample the original sample thousands of times
- Bootstrapping
- Pop. dist. of rule returns expected value is zero or less
- Data: Uses a daily history of rule returns
- Random sampling method: resampling with replacement
- Proprietary property of Quantmetrics Note I suspect this is very out of date. More info in the Google doc footnotes.
- Monte Carlo permutations
- Rule’s output values are randomly paired with future market price changes (random noise i.e. like a roulette wheel)
- Data: Daily history of rule output values, and daily price changes
- Random sampling method: pairs rule output values with returns without replacement
- Public domain
- Both rely on randomization (random resampling)
- Extensive tests by Dr. Timothy Masters, developer of Monte Carlo perms showed that both methods generally agree on detrended data
- Bootstrapping
- The bootstrap theorem
- Assumes that a correct sampling distribution will emerge as the sample size goes to infinity
- Given a single sample of observations, bootstrapping can produce the sampling distribution needed to test significance
- Aronson goes on to say that the current form of bootstrapping actually isn’t suitable for testing trading rules and doesn’t explain why BUT a modification by Dr. Halbert White (White’s Reality Check) in software called Forecaster’s Reality Check IS good enough (he says). Suffice to say I think it’s reasonable to assume the state of the art has progressed since then and I’m going to skimp on some details.
Attached Image
- All we need to know (I think)
- Detrended data (average daily change of zero)
- Zero-centered - makes mean daily return of the rule = zero; mean daily return value is subtracted from each daily return
- Number of observations in each resample must = the number of observations of the original sample
- Resamples produced by sampling with replacement so some rules might be selected more than once or not at all
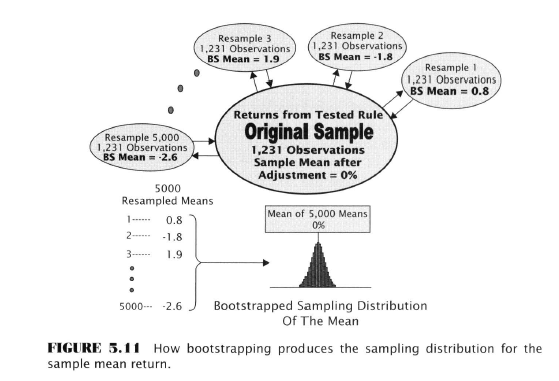
- 5,000 resamples in this case are taken, and a mean is computed for each one. The 5,000 means are used to construct the sampling distribution of the mean.
- Procedure
- Calculate mean daily return for the rule over 1231 observations in the original sample
- Zero centre by subtracting the mean daily return from each day’s return in the original sample
- Place the zero-centered data in a bucket
- Select a daily return at random from the bucket and note its value
- Place that return back in the bucket and randomize
- Repeat steps 4-5 N-1 times (1230) for a total of 1231 randomly selected observations
- Compute the mean return for the N observations in the first resample. This is one value of the mean.
- Repeat steps 6-9 a number of times (5000) producing 5000 boostrapped means
- Form the sampling distribution
- Compare the observed mean return of the rule to the sampling distribution and determine the fraction of the 5000 means that exceed the observed mean return of the rule to find the p-value.
Attached Image
- Monte Carlo Permutation Method (MCP)
- Invented by Stanislaw Ulam
- A general method for solving math problems by random sampling
- The particular method of using MCP to rest trading rules was developed by Timothy Masters
- The hypothesis tested by the MCP asserts that the returns are a sample from a population generated by a rule with no power so we need a method of simulating this
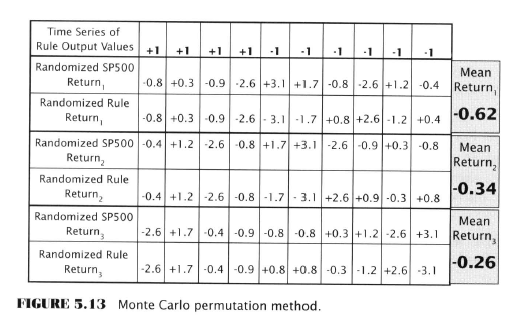
- The simulation is done by randomly pairing detrended daily returns with the ordered time series of the sequence of daily rule output values - see chart below
- The random pairing destroys any predictive power the rule may have had - the random pairing is called a noise rule
Attached Image
- MCP procedure
- Get or create a sample of one-day market price changes for the period of time over which the TA rule was tested, and detrend it
- Get the time series of daily rule output values over the back-test period. Let’s assume 1231 values, one rule output value for each day the rule was tested
- Place the detrended one-day-forward price changes in a bin and randomize
- Randomly select a market-price change from the bin and pair it with the first (earliest) rule output value. Don’t put it back in the bin.
- Repeat step 4 until all the returns in the bin have been paired with a rule output value. In this case 1231 pairings.
- Compute the return for each of the pairings, by multiplying the rule’s output value (+1 for long, -1 for short) by the market’s one-day-forward price change
- Compute the average return for all the returns in step 6
- Repeat 4-7 a large number of times (5,000)
- Form the sampling distribution of the 5,000 values obtained in step 8
- Place the tested rule’s rate of return on the sampling distribution and compute the p-value as the fraction of the random returns equal to or greater than the rule’s returns
- 91 day channel breakout example using DJIA Transportation Index
- Long and short on the S&P 500 index from Nov. 1980 - Jun. 2005
- Annualized return of 4.84 percent using detrended S&P 500 data to compute daily returns of the rule; a rule with no power is expected to have zero
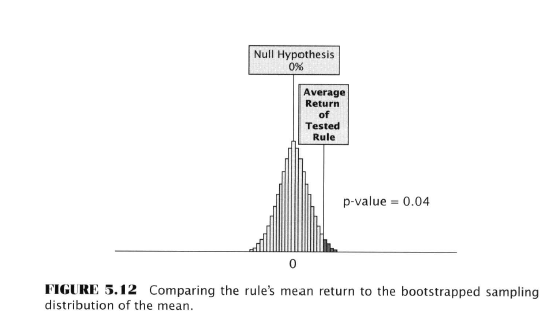
- Both bootstrap and MCP used to test the question - is the rule’s 4.84 % return sufficient to reject the null hypothesis?
- White’s reality check test (basically the bootstrap procedure outlined already)
- Results: Null hypo rejected - rule possibly is predictive (!)
- P-value of 0.0692 means 0.069 of the 5000 random means were equal or greater than 4.84%
- If the rule’s expected return was zero this would happen only 7/100 times due to chance
Attached Image
- Testing the 91-day channel breakout using MCP
- Again the procedure has already been outlined
- Results: support the possibility the rule is predictive!
Possibly, like me you were champing at the bit to know what the actual rule is that we can use to make money, but not so fast partner, that’s all revealed in chapter 8, the next to last one. First we have to look at Estimation.
- #63
- Jul 31, 2020 7:29am Jul 31, 2020 7:29am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Evidence-Based TA chapter 5 (part 3 of 3)
Estimation 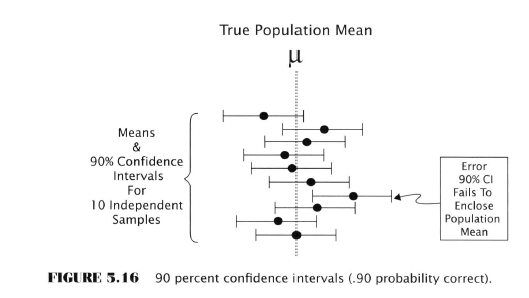
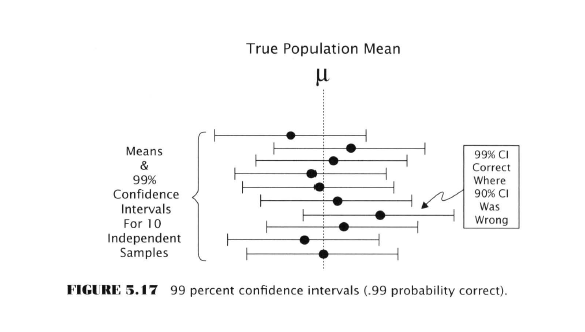
See how in the top diagram one of the samples is completely outside the true population mean? However the 99% probability intervals are all enclosing the true value.
This accuracy comes at the price of precision. The confidence intervals are wider in the second example.


Generating Confidence Intervals with the Bootstrap 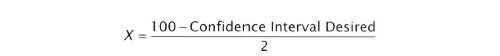
‘This book’ uses the sample mean as the performance statistic. And the Central Limit Theorem (law of large numbers) assures us that the sampling distribution will not be ‘seriously skewed’ as long as the sample size is ‘large’.
Confidence Interval for the TT-4-91 Rule
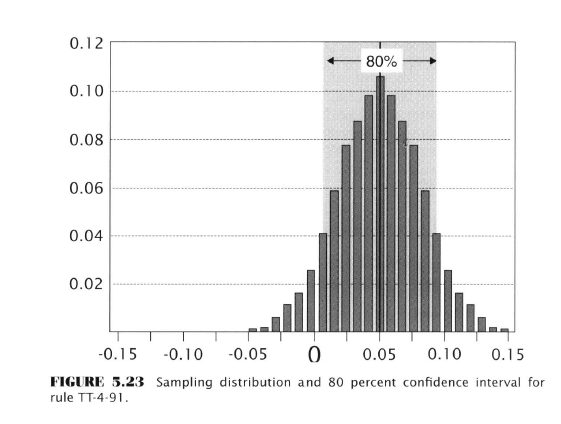
The 80% confidence interval is superimposed on the sampling distribution positioned at the rule’s back-tested return of 4.84 percent.
The lower bound is 0.62 percent. The upper bound 9.06 percent. So in 100 independent backtested samples, using 80% confidence, in 80 of the 100 samples, the true expected return value of the rule would be enclosed by the interval.
Estimation
- The ‘other’ form of statistical inference
- Hypothesis testing is about accepting or rejecting the claimed value of a population parameter
- Estimation is about approximating the value of the population parameter
- We’ll use it to estimate the expected return of a rule
- Types of Estimates
- Point Estimates
- A single value that approximates the pop. parameter
- “The rule has an expected return of 10 percent”
- Computed sample means were point estimates
- Other types are mean, median, standard deviation, variance
- Point estimate = sample statistic
- Interval Estimates
- A range of values where the pop. parameter lies with a given level of probability
- “The rule’s return lies within a range of 5-15 percent with probability of 0.95”
- Point Estimates
- Good estimators are:
- Unbiased
- Expected value = population value
- Deviations from the pop. value have an avg. value of zero
- Consistent
- Value converges to the value of the pop. value as sample size increases
- Efficient
- Produces the narrowest sampling distribution
- Produces the smallest standard error
- Sample mean is more efficient than the sample median
- Sufficient
- Makes use of all the available sample data such that no other estimator would add information about the parameter
- Unbiased
- The Confidence Interval
- A range of values surrounding the point estimate
- Upper and lower values = bounds
- Accompanied by a probability number, by convention a percentage
- More informative than point estimates
- Point estimates are limited because they give no sense of the uncertainty in an estimate due to sampling error
- By combining point estimate info and sampling distribution info the interval solves this
Attached Image
Attached Image
See how in the top diagram one of the samples is completely outside the true population mean? However the 99% probability intervals are all enclosing the true value.
This accuracy comes at the price of precision. The confidence intervals are wider in the second example.
Attached Image
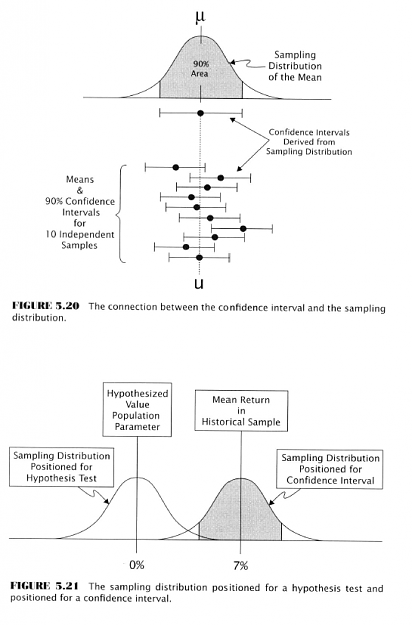
- Confidence Intervals and their Connection to the Sampling Distribution
- Confidence intervals are calculated from the same sampling distributions that give us p-values for a hypothesis test
- Sample mean = unknown pop. value +/- sampling error
Attached Image
Attached Image (click to enlarge)
Generating Confidence Intervals with the Bootstrap
- The procedure for generating confidence intervals with bootstrap is almost identical to the one we already saw for sampling distributions
- Bootstrap percentile Method
- Popular
- Easy to use
- Gives good results
- MCP cannot be used to generate intervals
- MCP tests claims about the information content of a rule’s signals
- No reference to a pop. parameter so there is nothing to create a confidence interval for
- Bootstrap Percentile Procedure
- Suppose rule returns resampled 5,000 times and a mean computed for each resample, so 5000 values for the resampled mean return
- Arrange 5,000 values in rank order from highest to lowest
- Remove highest x percent and lowest >x percent of values from the ordered list depending on the confidence interval desired.
Attached Image
- If a 90 percent interval is desired, remove the highest and lowest five percent of the values in the 5,000 value set. The remaining highest mean is the upper bound, and the lowest remaining resampled mean is the lower bound.
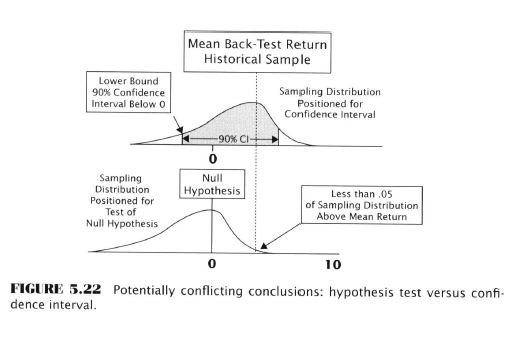
- Conflicts with Hypothesis Tests
- It is possible for a hypo test and a confidence interval to show different conclusions about expected return
- Hypo tests focus on the right tail of the sampling distribution
- Confidence intervals focus on the left tail of the sampling distribution
- If a sampling distribution isn’t symmetrical, it’s possible for for the hypo test to reject the null case where the confidence interval would give a low percentage chance that the rule’s return is zero or less.
- This is bad. They should agree.
- Asymmetrical distributions are ‘skewed’
Attached Image
‘This book’ uses the sample mean as the performance statistic. And the Central Limit Theorem (law of large numbers) assures us that the sampling distribution will not be ‘seriously skewed’ as long as the sample size is ‘large’.
Confidence Interval for the TT-4-91 Rule
Attached Image
The 80% confidence interval is superimposed on the sampling distribution positioned at the rule’s back-tested return of 4.84 percent.
The lower bound is 0.62 percent. The upper bound 9.06 percent. So in 100 independent backtested samples, using 80% confidence, in 80 of the 100 samples, the true expected return value of the rule would be enclosed by the interval.
- #64
- Aug 2, 2020 8:07am Aug 2, 2020 8:07am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
I'm just going to leave this here without much comment as I don't want to get into a fight with someone on this board who loves to pick fights, presumably since it puffs up their list of gulled followers. I have to admit I was fairly fooled by their initial logic and presentation. Be careful out there.
2
- #65
- Aug 2, 2020 8:57am Aug 2, 2020 8:57am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 6: Data-Mining Bias - The Fool’s Gold of Objective TA (part 1) 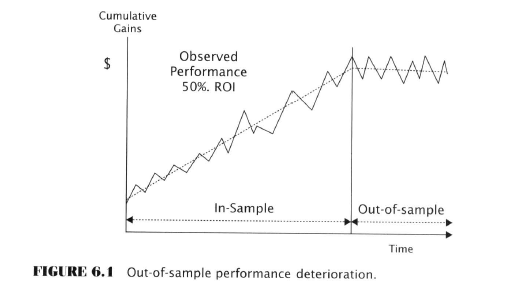
- When data mining rules, many are tested and the rule with the best observed performance is selected - it’s like a contest where the best performing rule wins
- The problem is that rule is unlikely to perform as well in the future for a number of reasons; we’ve talked about one before - survivor bias
- Data mining is still useful despite this problem
- Data mining is the process of looking for patterns, models, predictive rules, in large data sets
- In-sample data - data used for mining (rule back-testing)
- Out-of-sample data - data not used in mining or back-testing
- Rule universe - the full set of rules backtested in a data mining experiment
- Universe size - the number of rules making up the rule universe
Falling Into the Pit: Tales of the Data-Mining Bias
- Aronson tells a series of disconnected apocryphal stories that I’ll skip
- The main points are:
- Seemingly rare coincidences are quite probable if one searches enough
- Forming patterns without any logical framework is easy
- Hindsight can predict with 20/20 accuracy but never in advance of an event
- Data-mining bias is at heart a problem of faulty statistical inference
- Given enough opportunities randomness can produce extraordinary outcomes - for example a state lottery winner who won the big jackpot twice. Although the odds of this happening are 1 in a trillion, the odds of finding someone in the universe of all lottery players who has won twice is far higher - about 1 in 30.
- Excessive searching increases the chance of finding spurious correlations - such as an example the level of butter production in Bangladesh which correlated with the S&P500
The Problem of Erroneous Knowledge in Objective TA
- We’ve already seen how subjective TA can be erroneous
- Objective TA shows itself to be erroneous when out-of-sample performance deteriorates
Attached Image
- Explanations for deterioration
- Random variation (least plausible)
- Market dynamics changed as a result of being nonstationary systems
- “It would be implausible to suggest that market dynamics change as frequently as rules fail out of sample”
- The rule has been adopted by too many traders and is too well known
- Chance / Luck
- Data-mining Bias
- The process of data mining favors the selection of rules that benefited from good luck during the back test
Data Mining
- Extracting knowledge in the form of patterns from data
- Relies on computerized algorithms
- Aronson recommends two books
- Elements of Statistical Learning, Predictive Data Mining, a Practical Guide
- Data Mining: Practical Machine Learning Tools and Techniques
- Data mining as a multiple comparison procedure (MCP - not to be confused with Monte Carlo Permutation)
- MCP - test many different solutions to the problem and pick the one that performs best according to a criterion
- Requires:
- Well-defined problem
- Set of candidate solutions
- Scoring function that quantifies each candidates’ performance
- Requires:
- Types of Searches
- Parameter optimization
- Search universe is confined to rules of the same form but with different parameters
- Dual moving average crossover example
- 2 parameters - lookback periods for long and short-term averages
- Signals flash when short-term crosses long-term
- Optimization searches for the parameter values that yield the highest performance
- If we search for all the values without refinement this is a brute-force search
- One refinement is the genetic algorithm that uses performance of early results to guide later results
- Rule Searching
- The rules universe here is different in conceptual form and in parameters
- Part 2 of this book has a data-mining case study based on rule searching through rules of various categories
- Does not include combining simple rules, just uses a fixed number of params
- Rule Induction with Variable Complexity
- The broadest and most ambitious form of data mining
- Considers rules of undefined complexity
- Broadens search towards more and more complexity
- Uses machine learning (autonomous induction) to find the degree of complexity that produces the best performance
- One scheme uses individual rules, then pairs of rules, combined rules
- Genetic algos, neural networks, recursive partitioning, kernel regression, support-vector machines, boosted trees
- The Elements of Statistical Learning - Hastie, et al.
- Parameter optimization
- #66
- Aug 3, 2020 10:51am Aug 3, 2020 10:51am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Evidence-Based Technical Analysis Chapter 6 (part 2)
Objective TA Research 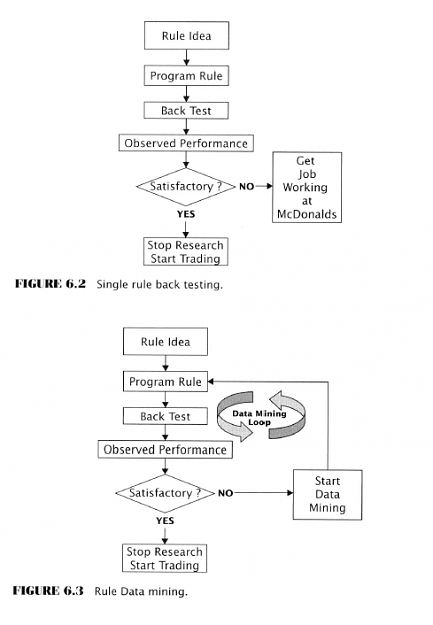
Objective TA Research
- The problem of out-of-sample performance failure discourages some objective TA practitioners from data-mining at all
- This is “Neither wise nor viable”
- Objective technicians who refuse to data mine are like taxi drivers with a horse instead of a car
- Experiments presented later will show that it works, with the more rules examined the more likely a good one will be found
- Tech trends favour data mining
- Cost-effectiveness
- Availability of software
- Availability of databases
- Currently TA lacks the theoretical foundation that permits more traditional scientific inquiries
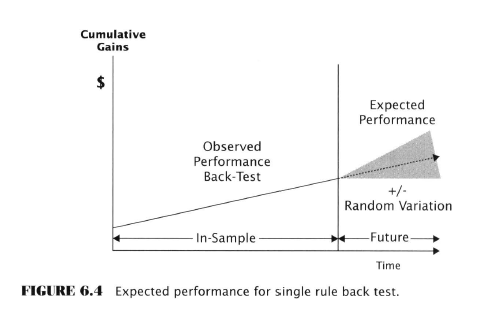
- Single rule back-testing vs. data mining
- When just a single rule is proposed and back-tested this is not data mining
- Data mining is back-testing of many rules and picking the best one of a group
Attached Image (click to enlarge)
- Cycle continues until a good rule is produced
- May involve tens, hundreds, thousands, or even more rules
- Legitimate uses of observed performance
- For a single rule, the back-tested return is most likely going to be the future return
- Recall from Ch. 4 a sample mean gives an unbiased estimate of the mean of the parent population that provides the sample. Random variation can produce error but it’s just as likely to be less than or more than the true value. In other words neither + or - error is more likely.
Attached Image
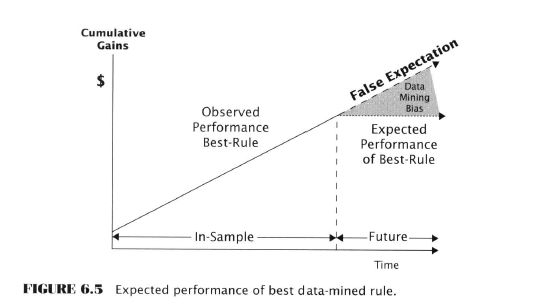
- In data-mining, the back-test performance stat plays a “very different” role than in single-rule testing
- Back-tested performance is a selection criterion.
- The rule with the highest back-tested mean return is likely to perform the best in the future. Not guaranteed but reasonably inferred and formally proven by White.
- The Data-Miner’s Mistake : misuse of observed performance
- The data miner’s mistake is to use the best rule’s back-tested performance to estimate the expected future performance
- Not legitimate because the best-performing rule is positively biased
Attached Image
- Out-of-sample deterioration is actually an illusion caused by assuming that the best-performing rule’s performance was not in part due to good luck
Data Mining and Statistical Inference
- Biased vs. Unbiased Estimators
- Error = observed values - true values
- Positive error is when observed is greater than true
- Negative error is when observed is less than true
- Biased error = systematic error, broken scale example
- Values lie on one side of the truth
- Over a large number of observations the biased errors do not average out but compound
- Unbiased error is “shit happens”, lab humidity example
- In a large number of observations this error is expected to average to zero
- Sampling error is unbiased
- Random error vs. Systematic Error
- Unbiased estimators are afflicted with random error
- Biased estimators are afflicted with both random error and systematic error
- Statistical Statements hold true for a large number of observations (law of large numbers)
- Data-mining bias shows up generally over many instances of data mining so “we cannot say any particular data-mined result is biased” (??)
- Mean vs. Maximum
- Single rule backtesters and data-miners are looking at different stats
- Single rule testers are observing the mean of one sample
- Data miners are observing the maximum mean among a multitude of of sample means - entirely different
- “The observed performance of the best-performing rule, among a large set of rules, is a positively biased estimate of the best rule’s expected performance because it incorporates a substantial degree of good luck.” Ok, so Aronson has said this about 10 times in different ways throughout the chapter. We get it, we believe you, professor!
- Sound inference requires the correct sampling distribution
- Data miners need the sampling distribution of the max mean among many means because that is the statistic being considered
Significance Test Comparison
We have to do a little Ch. 5 recap to make this comparison but realize this first bit is about single-rule testing.
- Null hypothesis says the trading rule return is expected to be zero or less
- Test statistic is the rule’s observed mean return - let’s say it was +10% annualized
- Sampling distribution of the test stat is centred at the theoretical return of zero
- The p-value is the area of the sampling distribution that >= a 10% return
- The area = probability that the rule could have produced a return of +10% if its expected return truly is zero
- If the p-value is smaller than a preset value like 0.05, the null hypothesis would be rejected, and alt hypothesis (rule is valuable) would be accepted
- This works fine as long as one rule was being evaluated
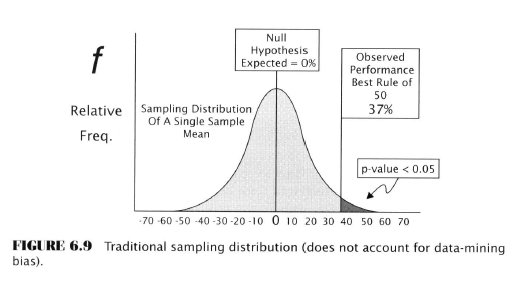
Now consider the case of the significance test for data mining:
- Assume that 50 rules have been back-tested
- Say the best-performing rule earned +37% annualized
- Significance test level of 0.05 would look like fig. 6.9
Attached Image
- Sampling distribution is centred at zero again
- Notice that the observed performance is far out in the right tail, giving a p-value of less than 0.05, based on this we’d reject the null hypothesis
- However, we’d be wrong!
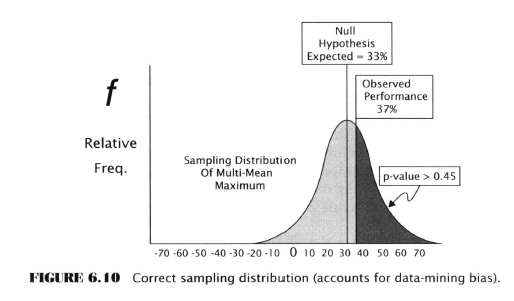
- Instead of using a standard sampling distribution we need to use a more advanced test that takes into account data-mining bias
- The observed mean return for the best rule out of 50 should be compared to the sampling distribution of the maximum mean among 50 means.
- This centers the distribution at 33 percent, not zero and looks like this:
Attached Image
- No longer looks significant - there is a 0.45 probability that the mean return of the best rule would be >= 37% due to chance
- #67
- Aug 4, 2020 3:47am Aug 4, 2020 3:47am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Evidence-Based Technical Analysis Chapter 6 (part 3)
Data-Mining Bias: An Effect With 2 Causes
The data-mining bias is the result of a combined effect 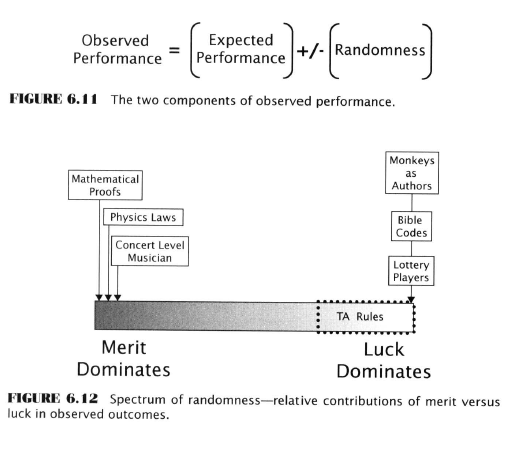
Interesting that mean reversion isn’t listed as a cause of rule performance deterioration - not yet at least

Recap 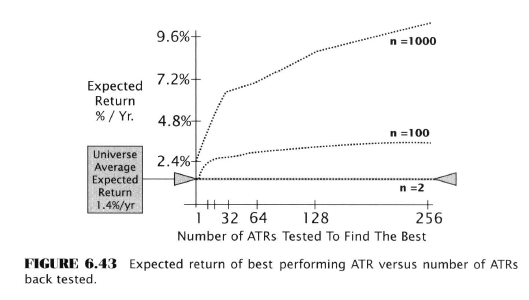
Aronson produces dozens of graphs like this one that all have the same message - more observations good, few observations, bad.
Next: Solution(s) to Data-Mining Bias
Data-Mining Bias: An Effect With 2 Causes
The data-mining bias is the result of a combined effect
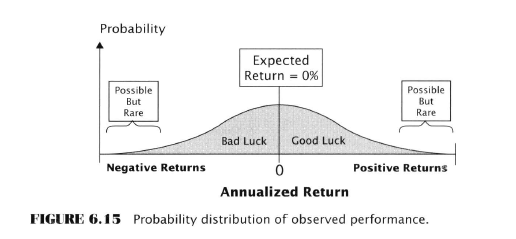
- Randomness
- The “Selection Imperative” of any multiple comparison procedure - picking the candidate with the best observed performance
- Two components of observed success for any rule
- True predictive power
- Randomness
Attached Image
- The effectiveness of Multiple Comparison Procedures (MCP) under Differing Conditions of Randomness
- The candidate with the highest performance is most likely to perform best in the future - TRUE - verified by Charles White
- The basic logic of data-mining is sound
- The performance is likely (reliable) in the future - NOT TRUE
- Jensen and Cohen show that when MCP is used in random conditions, the best performing rule overstates its future performance
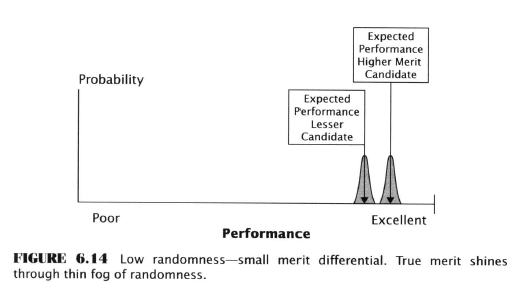
- The MCP in conditions of low randomness (example of hiring violinists for an orchestra) is much more effective
- In an orchestra observed performance is an accurate indicator of true merit, even though nerves, health, may have some effect on the sampled performance of any individual
- Over a large number of observations, the best performers will lead the pack
Attached Image
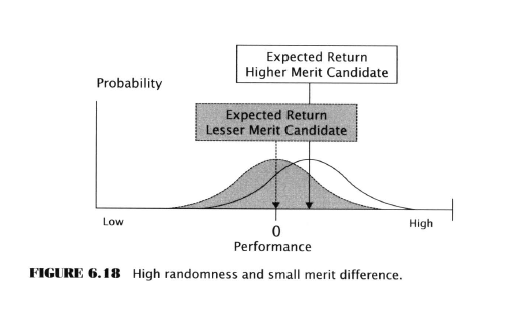
- The MCP in conditions of high randomness (market rule testing)
- Here randomness has a major impact on performance
- Although an extreme positive (or negative) return is unlikely for any individual rule it becomes increasingly likely with more rules tested, just as finding a lottery winner becomes more likely the more people play a lottery
Attached Image
Interesting that mean reversion isn’t listed as a cause of rule performance deterioration - not yet at least
Attached Image (click to enlarge)
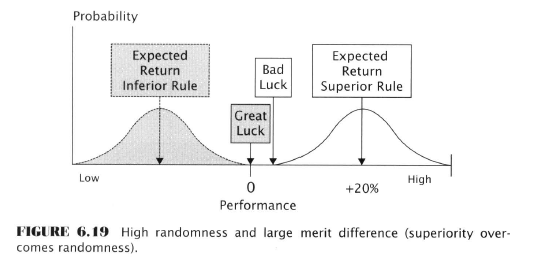
- The risk of picking an inferior rule
- Randomness could cause a rule that is not the best to be selected as the winner of a rule competition
- When the difference in merit (expected returns) is large enough between the best rule and second best, the data-miner can be more confident; merit is more likely to shine through the ‘fog of randomness’
Attached Image
Attached Image
Recap
- Data-mining bias is the expected difference between observed and true performance in a data-mining competition winner
- Observed performance is the level achieved by a rule in backtesting
- Expected performance is the theoretical future performance
- Observed performance of a contest winner is positively biased, therefore expected performance out-of-sample will be less than in-sample performance
- Observed performance is a combination of randomness and predictive power
- The more randomness contributes to the result, the greater will be the data-mining bias
Five factors determine the magnitude of the Data-Mining Bias
- Number of rules backtested
- Number of observations used to compute the performance statistics
- Correlation among rule returns
- Presence of positive outlier returns (Isn’t this randomness? Call it randomness.)
- Variation in expected returns among rules (again, randomness)
Experimental Investigation of the Data-Mining Bias
Here Aronson embarks on several pages of experimental testing to investigate the effect of the above five factors on data-mining. He decides to use something called “artificial trading rules” because these can be controlled to know their true population parameters. Sounds fishy, but probably soothing to an academic mind.
He generates ATR performance histories using Monte Carlo methods. He then compares single rule backtests to MCP tests. He shows how the data-mining bias increases with the addition of more rules. He emphasizes the importance of sample sizes on the magnitude of bias. He examines the effects of rule correlation. He looks at distributions with fat and light tails
Maybe I’m getting lazy but this just seems like overkill. Of course, good science has to do this, but for our purposes, let’s just stipulate the professor is right. All we need to know then is what we’ve already read.
- More rules = more bias, although the paradox is that more rules = more likely to find one that is actually good
- More observations reduces the effect of randomness, with too few observations, the observed rate of return of a rule is likely useless
- Rule correlation doesn’t have much effect on data-mining bias until the correlation approaches 1.0; the more correlation there is, the less chance the winning rule is significantly good, which is just intuitive
- Heavy tailed distributions = more randomness = bad for the data-miner
- Data-mining is still sound despite variation
- The less difference there is in true merit between rules, the bigger the bias
- Data mining works with large sample sizes, less so with smaller ones
Attached Image
Aronson produces dozens of graphs like this one that all have the same message - more observations good, few observations, bad.
Next: Solution(s) to Data-Mining Bias
- #68
- Aug 5, 2020 1:20pm Aug 5, 2020 1:20pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Evidence-Based Technical Analysis by David Aronson : Chapter 6 (part 4 of 4)
Solutions to Data-Mining Bias
Three solutions have been proposed 
Solutions to Data-Mining Bias
Three solutions have been proposed
- Out-of-sample testing
- Excluding a subset of data from the mining sample which is then used to evaluate the best rule that was discovered in-sample
- This un-mined data provides an unbiased estimate of its expected future return
- How to best segment historical data into in and out of sample?
- Easiest is to split into two parts
- Early portion is reserved for mining
- Later portion is used for out-of-sample testing
- More sophisticated schemes segment the data in narrower bands of in and out samples, so that the history is broken up better
Attached Image
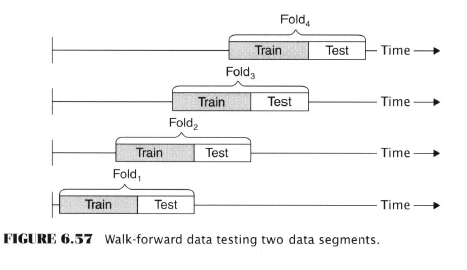
- Walk-forward testing
- Another data segmentation approach
- Pardo, De La Maza, Katz, McCormick, Kaufman
- Uses a moving data window, which is itself divided into in/out sample segments
- Alludes to a rule that is being adjusted as the market “evolves”
- In-sample segment is the ‘training data’, where the best parameter values are discovered
- The out-of-sample set is the ‘testing data’, where the best parameters are tested
- Disadvantages:
- Short life span of unused data. Once used, it cannot be re-used.
- Reduced total data available for testing since a portion of it needs to be reserved.
- No theory governing what fraction of data should be assigned to training and testing
Attached Image
- A data-mining correction factor (Markowitz and Xu)
- Deflates the observed performance of the rule that wins
- Can work surprisingly well or fail miserably, according to Aronson depending on ‘conditions’
- Doesn’t require data segmentation
- Requires complete set of interval returns for all rules examined.
- Performance deflation is determined by factors like the degree of variation in each rule’s daily returns, mean returns, the number of rules examined, the number of time intervals
- Disadvantages:
- Results are approximate
- Useful as a rough guideline only
- Randomization methods (White’s Reality Check and MCP)
- Not widely discussed outside of academia
- Uses methods “like” bootstrapping and Monte Carlo
- Allows testing of as many rules as desired
- Whole data set can be used for testing
- Permits significance testing
- ‘Sometimes’ produces confidence intervals
- Disadvantages:
- Both suffer when the data-mined universe contains rules that are worse than useless (contrary indicators)
- Both are subject to the type 1 and type 2 errors of hypothesis testing
Aronson promised to put the software used for the MCP version on his website but I don’t see it. Some source code is in the Monte Carlo PDF.
- #69
- Aug 6, 2020 7:19am Aug 6, 2020 7:19am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 7: Theories of Nonrandom Price Motion
If you've gotten this far, well done. You have the mettle that makes of mortals laurel-wreathed champions, and maybe, just maybe, traders par excellence.
The next two chapters are your reward for grinding this rather dry material for now we will see if we can actually derive some rational theories behind forecastable patterns in the market. Most traders ask 'how' but they rarely ask 'why'. If we can't answer that question it makes everything we believe, and our actions based on those beliefs, questionable. 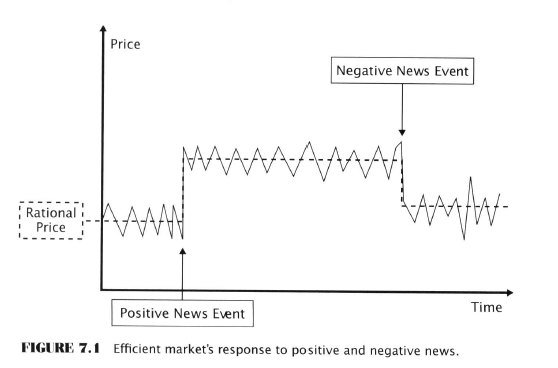
If you've gotten this far, well done. You have the mettle that makes of mortals laurel-wreathed champions, and maybe, just maybe, traders par excellence.
The next two chapters are your reward for grinding this rather dry material for now we will see if we can actually derive some rational theories behind forecastable patterns in the market. Most traders ask 'how' but they rarely ask 'why'. If we can't answer that question it makes everything we believe, and our actions based on those beliefs, questionable.
- If market fluctuations were completely random, TA would be pointless
- Markets have to be nonrandom at least some of the time to justify efforts spent in forecasting
- Even if there is nonrandom price motion, this isn’t enough to justify any specific method
- Each method must demonstrate, by objective evidence, ability to capture some part of that nonrandom price movement
The Importance of Theory
- New theories from the field of behavioral finance explain why price movements are nonrandom to some degree
- These theories take a position contrary to the Efficient Market Hypothesis (EMH), a cornerstone of market theory for over 40 years
- Why is theoretical support for nonrandomness even necessary? If we have a profitable backtest isn’t that all that’s needed?
- After all the test proves that the markets are nonrandom and that we can make profit, right?
- Without theoretical support, a backtest, even a profitable one, could simply be the result of luck. Like I said in this chapter’s intro - we need to say ‘why’ not just ‘how’
- A backtest that is consistent with theory is less likely to be a statistical fluke
- An example is the justification for trends in commodity futures; they are ‘compensation’ for providing a valuable service to commercial hedgers, the service being risk transference
Scientific Theories
- Theories are speculative, but scientific theories, as explained in ch. 3 are better
- They make specific predictions confirmed by later observations - ex. being Kepler’s laws
- What’s wrong with popular TA Theory?
- Aronson is never shy about repeating himself - we have heard all his reasoning against Elliott et al so I’ll try to do a big summary
- TA texts rarely offer explanations and when they do they are ‘ad hoc’ rationales with no testable premise
- John Murphy - “Anything that can possibly affect the price - fundamentally, politically, psychologically or otherwise - is actually reflected in the price of that market.”
- Such a vague statement cannot make testable predictions
- Such a statement is also logically contradictory. If price already contained all info it would then be devoid of predictive info. Because if there was anything to predict the price would already be at that level dictated by the prediction.
- EMH’s basis is that all info available is reflected in the price, and EMH rejects TA
- Technical analysis cannot be based on the same premise as its mortal enemy
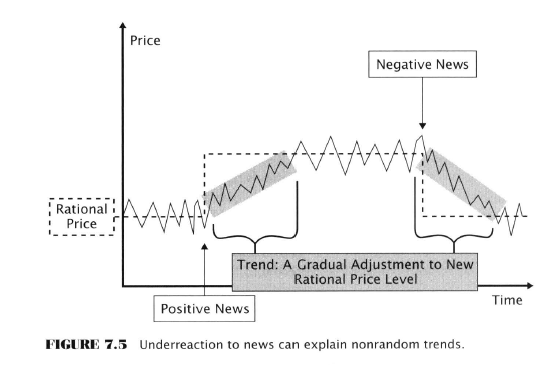
- Underreaction Effect
- Prices sometimes fail to respond to new info as rapidly as EMH theorists believe which gives rise to trends as prices ‘catch up’ to the info
- Failure to respond rapidly is caused by human biases like conservatism bias and the anchoring effect
- Pop psychology - meaning psychology with no scientific support
- Robert Shiller: “In considering lessons from psychology, it must be noted that many popular accounts of the psychology of investing are simply not credible. Investors are said to be euphoric or frenzied, during booms or panic-stricken during market crashes. ...The fact is, people are more rational than these pop-psychology theories suggest.”
- During the most significant financial matters most people are preoccupied with personal matters, not with markets, so it’s hard to imagine the market is reacting to the emotions of these theories.
The Enemy’s Position: Efficient Markets and Random Walks
- Recently ‘some’ have suggested that random walks (market efficiency) and price predictability can coexist.
- What is an efficient market?
- A market that cannot be beaten
- No fundamental, technical strategy, formula or system can earn a risk-adjusted return that beats the market defined by a benchmark index
- Buying and holding the index is the best you can hope for
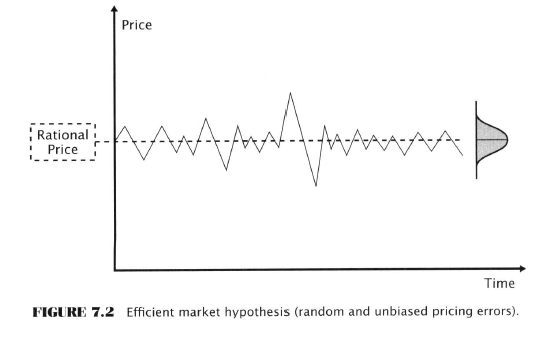
- The combined work of rational investors causes prices to settle in an equilibrium or rational price level
- Prices change only when new info arrives
Attached Image
- Consequences of market efficiency, good and bad
- Good for the whole economy
- Bad for TA (and traders)
- A blindfolded monkey could do as well as an expert
- Rules out the possibility of trading systems
- Resources spent on analyzing, picking and trading securities are wasted
- Returns can still be generated but when they are adjusted for risk they will not beat the market index portfolio
- When there is no news entering the market prices oscillate randomly and unbiasedly above and below the rational price level
Attached Image
- False notions of market efficiency
- Efficiency requires the market price to be equal to the rational value at all times - FALSE; it simply requires that price deviates from rational value in an unbiased fashion. Negative and positive deviations are equally likely
- “The time series of pricing errors in an efficient (forex?)market is a random variable whose probability distribution is centered at the rational price and is approximately symmetrical about it.”
- No one can beat the market - FALSE; actually at any given time about 50% of all investors will outperform the benchmark index, while the other 50% underperform
- No single investor or market manager can beat the market long-term - FALSE!; Given enough players, a small number are likely to have long streaks. Remember Taleb - and survival bias?
- Efficiency requires the market price to be equal to the rational value at all times - FALSE; it simply requires that price deviates from rational value in an unbiased fashion. Negative and positive deviations are equally likely
- Evidence in favour of EMH
- Recall:
- Scientific hypothesis has two roles - explanation and prediction
- Its truth is tested by comparing observations with its predictions
- Predictions must be specific enough to be falsified in order to be meaningful
- If new observations contradict a hypothesis’s prediction it is reformulated or thrown out
- If observations confirm the hypothesis it is retained, unless you’re David Hume then you won’t accept any correlation between cause and effect

- Semistrong Form
- Asserts it’s impossible to beat the market with public info, including all technical and fundamental analysis
- Not specific enough to be testable but it does conform to the experiences of many traders
- Some specific predictions are testable
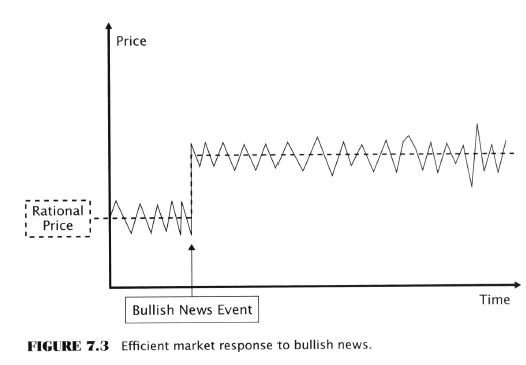
- A security’s price will react quickly and accurately to any news that bears on its value
- Recall:
Attached Image
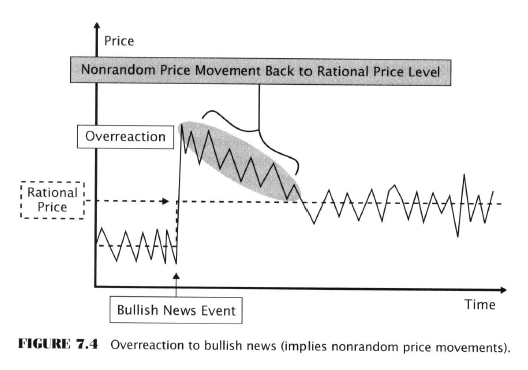
- Obviously this is NOT what happens when news is released.
- EMH denies predictability so it must also deny overreactions to news,
- It must also deny underreactions
- Eugene Fama found evidence supporting this
- After an initial un-exploitable instantaneous price movement reaction triggered by news there was no additional movement.
- Another prediction is that price should not change much in the absence of news or due to non-informative events
Attached Image
Attached Image
- Stale information should have no effect on prices
- All TA qualifies as ‘stale’ information
- To prove any of this we need to quantify risk so that we can define ‘risk-adjusted returns’ This needs its own chapter Aronson!
- The most well-known risk model is the CAPM (capital asset pricing model) which explains systematic differences in the returns of securities in terms of a single risk factor, the relative volatility of the security.
- If a stock is twice as volatile as the overall market, then it should return twice as much, basically, that’s ‘excess returns’
- CAPM cannot quantify the risk of more complex securities, and derivatives
- So we need another model - ABT - ‘arbitrage pricing theory’ which attributes risk to several independent risk factors
- EMH advocates keep cooking up new risk factors in order to extend the amount of evidence needed to refute their claims
- Aronson rants about this in several places
- Weak Form
- States that stale prices and indicators derived from them, like momentum indicators, are worthless, based on auto-correlations studies
- These studies do show that price changes (returns) are linearly independent, so a linear function of current and past returns cannot be used to predict future returns, so - random walk
- However autocorrelation studies are relatively weak tests in the sense that they can only detect linear dependencies
- Peters, Lo, MacKinlay, have shown that alternative data analysis methods indicate that financial market time series do not behave like random walks
- They developed a ‘variance ratio’ to detect more complex (nonlinear) nonrandom behaviours invisible to autocorrelation
Next - Refuting the EMH!
Google Doc (footnotes - recommended for this chapter esp.)
- #70
- Edited Aug 8, 2020 10:16am Aug 7, 2020 3:42pm | Edited Aug 8, 2020 10:16am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 7: Theory of Nonrandom Price Motion (part 2)
Challenging the EMH
A theory can be challenged either by showing that it contradicts itself or that is contradicted by evidence.
A cornerstone premise of EMH is that price perfectly reflects all information, contradicting the notion that price contains predictive information. 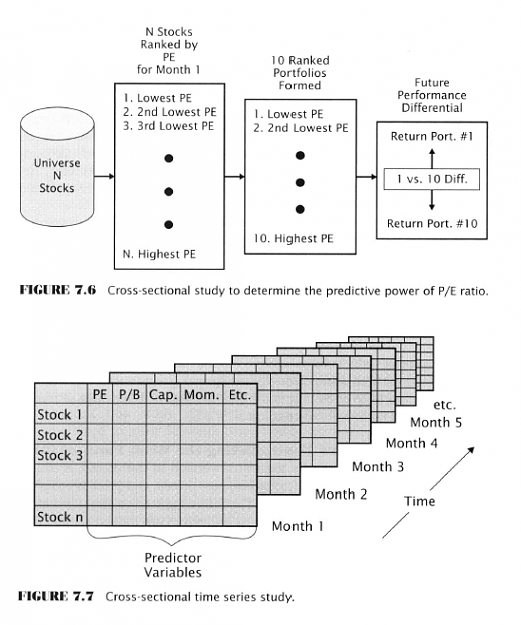
The semi-strong form of EMH is the boldest testable form of EMH. It asserts no info in the public domain, fundamental or technical can be used to generate risk-adjusted returns in excess of the market index.
Challenging the EMH
A theory can be challenged either by showing that it contradicts itself or that is contradicted by evidence.
A cornerstone premise of EMH is that price perfectly reflects all information, contradicting the notion that price contains predictive information.
- Smart vs. Dumb Paradox
- Knowledgeable investors should not be able to earn higher returns than investors who are less knowledgeable
- In an efficient market there is no advantage to being smart or disadvantage to being dumb
- This conflicts with another EMH assumption - that arbitrage activities of rational investors are able to drive prices toward rational levels
- Arbitrage can only act as an enforcer if arbitrageurs have more capital
- This implies that arbitrageurs have been more successful in markets than less well informed (dumb) investors
- Either market prices are set by the smartest, richest participants, or they are not
- EMH implies both - which is a paradox
- The cost of Information Paradox
- It is reasonable to assume it costs time, money and intelligence to gather information and process it into useful investing strategies
- However EMH contents that such information cannot earn incremental returns for investors who incur those costs
- There is therefore no motivation for anyone to dig out the information and act on it
- And therefore no mechanism to keep prices updated
- Grossman & Stiglitz - “On the Impossibility of Informationally Efficient Markets”
- They argue inefficiencies are necessary to motivate rational investors to gather and process info
- Their returns are compensation for this work, which moves prices to rational levels
- Their gains are financed by ‘noise traders’ and liquidity traders.
- Noise traders buy on sell on worthless signals
- Liquidity traders trade to increase their cash reserves
- Unless traders were compensated for their costs (commissions, slippage, spreads), there would be no point in their trading which is required for rational levels
- Trading costs and rules that limit trading (like short-selling disincentives) limit the ability of the market to be rational
- The Assumptions of EMH
- Investors are rational
- They value securities correctly
- Prices reflect the present discounted value of a security’s future cash flows and risk characteristics
- They respond quickly to new info, so prices adjust almost instantly
- Investor’s pricing errors are random
- The valuation mistakes of individual investors are uncorrelated
- They average out and offset each other
- There are always rational arbitrage investors to catch any pricing errors.
- If the previous assumption is incorrect and the flawed evaluations of traders gets out of hand, arbitrageurs will be there to bring prices back to reality
- Arbitrage - the free lunch In the EMH ‘world’
- An arbitrage transaction incurs no risk
- Requires no capital
- Earns a guaranteed return
- Example arbitrage trade in the minds of EMH supporters
- Consider two stocks, X and Y
- Selling at equal prices, equally risky
- Different expected future returns But then why aren’t their prices different? Huh? HuH?!!!!
- One is improperly priced that’s why, smart guy
- Arbitrageur buys asset X, and shorts asset Y
- All rational arbs do this and the prices converge to their ‘proper’ values
- Assumes there are always willing and able arbs ready to do their duty
- The rational (skilled) ones get rich and the bad ones lose their ability to push prices
- The uninformed irrational investors are driven out of the market the way an unfit species is extinguished from an ecosystem
- Investors are rational
- Flaws in EMH assumptions
- Investors are NOT rational
- They react to irrelevancies
- They trade on noise
- Their returns are random coin flips
- Investors who follow gurus are noise traders by proxy
- Fail to diversify
- Overtrade
- Sell appreciated stocks but hold onto losing trades,
- Fail to optimize for taxes
- Make recurring errors
- Investor’s deviations from economic maxims of rationality are ‘highly pervasive and systematic’.
- 3 categories of irrationality
- Inaccurate risk assessments
- Investors don’t assess risks systematically for example employing something like ‘expected utility theory’ (Neumann & Morgenstern)
- They behave more like what is described in ‘Prospect Theory’ (Kahneman and Tversky) - selling to avoid loss which is more painful than gains are pleasurable.
- Poor probability judgments
- Investors don’t update their judgments based on new info
- EMH assumes investors use Bayesian probabilities
- Instead they draw conclusions from small data samples
- For ex. Buying a stock with a short-lived string of good quarterly reports
- Irrational decision framing
- Investors are susceptible to how choices are described (framed)
- Investors will assume the risk of a significant loss just to avoid a certain loss if a choice is framed in terms of loss
- This is called the ‘disposition effect’ (Kahneman again?)
- Investors sell winners quickly
- Hang on to losers
- Inaccurate risk assessments
- Investor errors ARE correlated
- Psychological research shows people do not deviate from rationality randomly in uncertain situations
- Most people make similar mistakes
- FOMO/social proof - investors copy each other and repeat other’s mistakes
- Herding
- Money managers are not immune
- They construct portfolios that are excessively close to the benchmarks they use to avoid any chance of losses
- They move herd-like into the same stocks
- Arbitrage does not force prices to rational levels (necessarily)
- Arbitrageur power is limited
- There is no bell when securities are mispriced
- Future earnings are estimates only, so the rational price is always being discovered
- Arbitrageurs don’t have unlimited tolerance for adverse price moves
- Noise traders can push prices further from rationality even after it spotted
- If this happens often enough noise traders can drive ‘rational’ traders out of the business - noise trader risk
- Shleifer - even perfect arbitrage trades are risky, so the number of traders engaged are limited
- Noise trader risk was a factor in the blowup of LTCM
- Overleveraging is another risk
- The Kelly Criterion - specifies the optimal fraction to be on each coin flip to maximize the growth rate of bettor’s capital - depends on win probability and the average win/average loss ratio
- Lack of perfect substitute securities - an ideal risk-free arb involves simultaneously buying and selling two similar securities in terms of future cash flows and risk; if they’re not the same there is more risk
- Limited funds - arbitrageurs manage money for other investors and are limited in the amount of risk they can afford
- Empirical Challenges to EMH
- Excessive Price Volatility
- If security prices are tightly coupled with fundamental values as EMH predicts, then the magnitude of price changes should match changes in fundamentals
- This is not the case as stock and asset bubbles show especially when fundamental value is defined as future dividend values
- Prices don’t just change when significant new info enters the market
- There was no news before the 1987 crash
- Research (orange juice prices, largest one day price moves) shows many of them aren’t accompanied by news
- Excessive Price Volatility
- Evidence of Price Predictability with Stale Info
- Strategies based on stale info can generate market-beating risk-adjusted returns
- If prices quickly incorporated all known info, this should not be possible
- Cross-Sectional Predictability Studies
I have to complain about why this idea is only being introduced now. This type of study would have been far more interesting than multiple appeals to the law of large numbers in previous chapters.
- Predictability studies use a cross-sectional design
- They examine a large cross-section of securities at a given point in time
- They are ranked on the basis of some indicator - like the rate of return over the past six months (price momentum)
- Then they are arranged into a number (say 10) of portfolios on the basis of the ranking
- Portfolio 1 contains the top 10 percent of all stocks over the last 6 mos.
- Portfolio 10 contains the bottom 10 percent of all stocks over the last 6 mos.
- To see if six months of momentum carries over to the next month buy portfolio 1 and short portfolio 10
- You could use any indicator - P/E, etc.
Attached Image (click to enlarge)
The semi-strong form of EMH is the boldest testable form of EMH. It asserts no info in the public domain, fundamental or technical can be used to generate risk-adjusted returns in excess of the market index.
- The bottom line of numerous studies:
- Price movements are predictable to some degree with stale public info and excess risk-adjusted returns are possible. The following section is golden. More for me if you don't read it.
- Small cap effect - A stock’s total market cap is a drag on its returns. Stocks in a portfolio made up of the lowest decile of market capitalization 9 percent more per year than stocks in the highest decile portfolio. Most pronounced in January (???) This effect has disappeared since the 1980s, because it was cyclical, probably.
- Stocks with low P/E ratios outperformed stocks with higher P/E ratios
- Price to book value effect - stocks with low price to book value ratios (P/B) outperform stocks with high price to book value ratios. The cheapest stocks, in terms of price to book, outperform the most expensive stocks by almost 20 percent per year.
- Earning surprises with technical confirmation; unexpected positive earnings, or earnings guidance, confirmed by strong price and volume the same day or day after announcement, earn annualized returns (longs-shorts) over the next month of 30 percent. This is fundamental + technical info.
- Predictability studies contradict weak EMH
- The weak form is the least bold - it claims only a subset of public info, past prices and price returns is unhelpful in earning excess returns - this also makes it the most difficult to falsify
- Studies that show stale prices and other data in TA is useful, bad for EMH, good for for TA
- Momentum persistence
- Jegadeesh and Titman (1993) showed price momentum measured over six-12 months
- The strongest stocks over the past 6-12 tend to outperform over the following 6-12 mos.
- They used the decile strategy described in this chapter
- Annualized return of 10 percent; even Eugene Fama had to recant
- Momentum reversal
- Strong trends over 3-5 years display a tendency to reverse
- DeBondt and Thaler
- Tested a strategy buying stocks with the most negative five year trends (long) and selling short stocks with the most positive five year returns (short)
- The long versus short portfolio earned 8 percent annualized over 3 years
- Prior losers (future winners) were not riskier than prior winners (future losers)
- Contradicts EMH proposition that higher returns can only be earned by assuming higher risks
- Supports the notion that a simplistic form of TA is useful.
- Nonreversing momentum
- When measuring stocks by their proximity to their 52 week high, profits are greater and momentum does not reverse
- Michael Cooper
- Speculates investors are anchored to prior 52 week highs
- Therefore they don’t respond to fundamental developments as quickly as they should
- Momentum confirmed by trading volume
- Synergism can be obtained by combining price and volume indicators
- 2-7 percent higher than just price momentum alone
- Stocks with higher volume and positive price momentum do better than using momentum alone, and for negative price momentum they do worse
- Momentum persistence
- EMH Digs for a Defense
- French & Fama chief supporters (Aronson says ‘pallbearers’)
- Science advances one funeral at a time - adherents to a failed theory don’t just rollover and accept new ideas, they have to fade away and be replaced
- As long as the term ‘risk’ is undefined, EMH defenders can say that returns from stale information such as PB ratios and market capitalization are fair compensation for risk
- They can come up with new forms of risk after the fact
- Elliott Wave supporters use ‘after the fact fiddling’ to explain away contrary observations and EMH supporters do the same
- Fama and French invented a new ad hoc risk model to replace CAPM which only uses on risk measure - volatility relative to the market index
- Naturally they picked PB ratio and market cap saying companies with low values are fundamentally riskier and must offer higher average returns to compensate investors, the reverse being true for high cap blue chips
- “Nothing more than an ad hoc after-the-fact explanation conjured up to save a dying theory”
- However if it were true then value strategies (low PB stocks) and small cap stocks would earn subpar returns in bad economic times
- Empirical evidence contradicts this prediction
- 1994 study (footnote 60 in Aronson’s notes)
- The disappearance of the cap size excess returns is also a problem for EMH
- Cannot explain price momentum and price momentum + volume conjoint performance
Next: Behavioral Finance : A Theory of Nonrandom Price Motion
1
- #71
- Aug 8, 2020 10:44am Aug 8, 2020 10:44am
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 7: Theory of Nonrandom Price Motion (part 3)
Behavioral Finance: A Theory of Nonrandom Price Motion 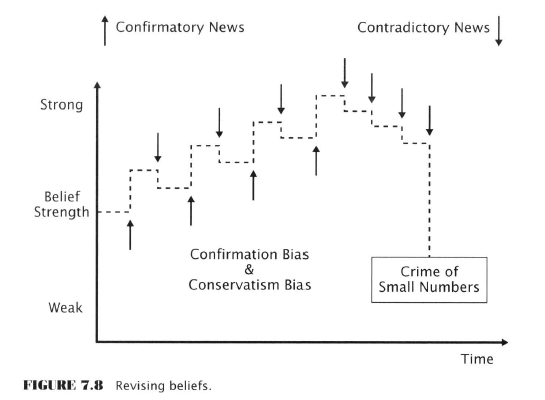
Financial markets depend on a healthy balance of positive/negative feedback 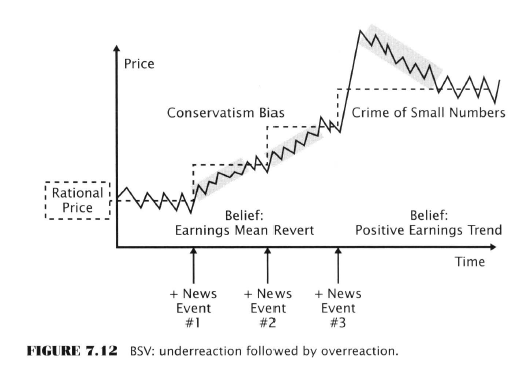
Behavioral Finance: A Theory of Nonrandom Price Motion
- A new theory is needed to replace EMH
- Behavioral finance (BF) makes testable predictions (scientific) and it incorporates elements of cognitive psychology, economics and sociology to explain why investors depart from rationality and why markets aren’t efficient
- BF sees the market as a mix of decision makers who vary in rationality
- Market efficiency declines when noise traders (irrational) trade with rational agents (arbitrageurs)
- Market efficiency is a special condition that is much less probable than other plausible conditions, where prices diverge from rational levels and thus likely to experience systematic predictable movements toward those levels.
- Hence why systematic strategies can profit
- “That which explains the foolishness of subjective TA practitioners also explains the reasonableness of some objective TA methods” (cognitive errors)
Foundations of Behavioral Finance
BF rests on two foundational pillars:
- Limited ability of arbitrage to correct pricing errors
- Not a perfect enforcer of efficient pricing
- Add to this the impact of noise traders acting on random signals
- Limits of human rationality
- Limits of arbitrage don’t tell us under what circumstances markets are more likely to underreact or overreact
- Cognitive psych tells us humans err in predictable ways in some circumstances
- A lot is still not known about investor irrationality
- EMH and BF agree that eventually the market gets it right- prices converge toward rationality
- BF says some departures are systematic and last long enough to be exploited by investment strategies
- Psych factors
- Conservatism bias
- Tendency to give too little weight to new info
- As a consequence the market tends to underreact
- The gradual acceptance of reality manifests on the chart as a price trend
- Confirmation bias
- Tendency to accept information that is consistent with prior beliefs and to reject evidence that contradict prior beliefs
- Causes beliefs to become more extreme over time
- Prior beliefs can “radically and irrationally weaken” if several pieces of contradictory info arrive in a streak
- Streaks are common in random sequences but humans see them as patterns/evidence and attribute too much significance to them
- Belief inertia
- Caused by above and
- Anchoring bias - the first quantity is used for future heuristics despite how off it may be
- Investors anchor not only to numbers but also to stories (news)
- Conservatism bias
Attached Image
- More biases
- Optimism and overconfidence
- Sample size neglect (crime of small numbers)
- Gambler’s fallacy
- Clustering illusion
- Social proof
- Herding (can be rational)
- People operate with an implicit rule, “the majority is unlikely to be wrong”
- Individuals take actions that are fully rational on an individual basis but harmful to them as a group
- Information cascades
- Information Cascades and Herd Behaviour
- Investing is hard so it’s more likely investors will rely on imitation than independent thinking Forum-goers prove this 99% of the time, Clemmo’s Theorem is a stronger form of this postulate
- Info cascade is a chain of imitative behaviour initiated by one or a few individuals, even if the original choice was random
- The restaurant parable - by chance a few people wander into one of 2 new restaurants
- People on the street see that one restaurant is empty and avoid it
- The other one fills up.
- One restaurant goes bust and the other booms purely by chance
- This is a bit of a ‘Buridan’s ass’ thought experiment absurdity because no two restaurants are perfect substitutes
- Diffusion of Information among investors
- Shiller: word of mouth is strong even in people who read a lot
- Epidemiological models have been used to study info flow through investment communities but hey have not been as successful as biological models
- Investors can hold contradictory ideas that lie ‘inert’ and a story will activate that idea in their minds (??)
- Shifts in investor attention
- Humans are bad at attention splitting
- In order to filter out irrelevant info we look to others for cues
- ‘We’ presume what grabs the attention of others must be relevant to us
- Shiller: “the phenomenon of social attention is [...] critical for the functioning of human society”
- Shiller: Even institutional investors are prone to buying stocks simply because they had a big price increase
- Shiller’s studies show that investors are not even aware that it was a dramatic price movement that motivated them to act.
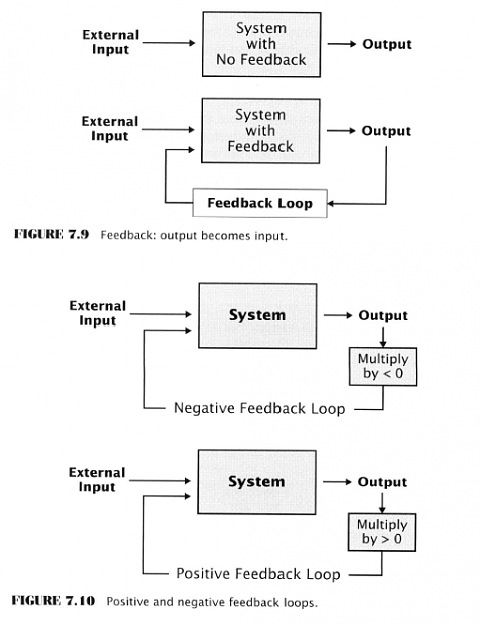
- Feedback in systematic price movements
- Social interaction creates feedback
- Feedback is the channeling of system output back into the system as input
- Positive feedback - multiplier is a positive number
- Increases system behaviour
- Microphone screech example
- Negative feedback - multiplier is negative
- Dampens system behaviour
- Household heating/cooling example
Attached Image (click to enlarge)
Financial markets depend on a healthy balance of positive/negative feedback
- Arbitrage - negative feedback
- Crowd herding - positive feedback
- Positive feedback can lead to bubbles and crashes
- Mental accounting
- Irrational tendency to think of money as if it belonged in separate accounts that should be treated differently
- “Rationally, all of an investor’s money, regardless of how it was made or in which asset it is invested should be treated in the same way.”
- At some point the increasing expectations that fuel a bubble run out
- They can end in a crash or
- Just peter out in a series of jagged declines
- Self-organizing Ponzi schemes
- Shiller: believes that Ponzi schemes confirm the feedback theory
- Ponzi schemes are pyramid schemes where later investor money is used to pay off earlier investors, fuelling the notoriety of the scheme
- They inevitably end with later investors losing everything and the scheme collapsing with only the originator or the first level of investors seeing profit
- Shiller: speculative bubbles are naturally occurring Ponzi schemes that emerge spontaneously without requiring fraud
- Self-organizing behaviour is common in complex systems
- Competing hypotheses of BF
- Barberis, Shleifer, Vishny (BSV)
- Confirmation bias & sample size neglect
Attached Image
- Daniel, Hirshleifer, Subrahmanyam (DHS)
- Endowment bias, confirmation bias, and self-attribution bias (see ch. 2 notes)
- Investors have too much confidence in their own private research
- News, and info, is usually treated as confirmatory whether it actually is or not
- If DHS & BSV are valid then profits earned by strategies that exploit trend reversals should be concentrated at the times of information releases
- A large fraction of excess returns earned by buying value stocks (low p/b, low p/e) and buying the weakest stocks of the past 3-5 years do occur near the times of earnings releases
Next: News traders, momentum & Hong-Stein +
Nonrandom price motion and efficient markets can coexist maybe???
1
- #72
- Aug 9, 2020 1:13pm Aug 9, 2020 1:13pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 7: Theory of Nonrandom Price Motion (part 4 of 4)
News traders and momentum traders: the Hong-Stein hypothesis 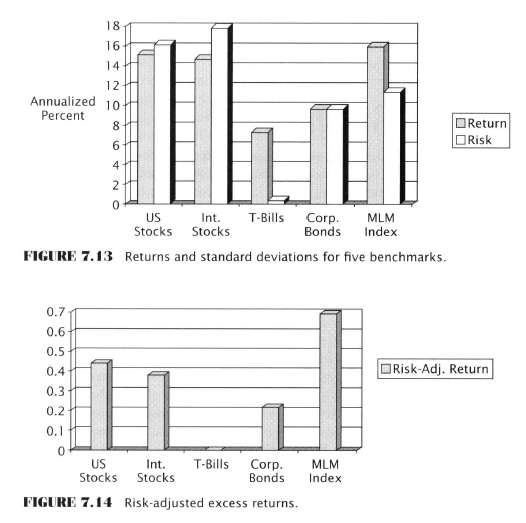
The way the Fed transfers risk away from investors is not even considered by Aronson though.
Liquidity premium and the gains to counter-trend trading in stocks
News traders and momentum traders: the Hong-Stein hypothesis
- Price momentum could be explained by prices catching up to fundamentals due to an initial under/overreaction
- It can also be explained by positive feedback, where a price change stimulates additional buying or selling
- Trends spawned by positive feedback can be seen as a cascade of progressively less sensitive trend-following signals that get triggered
- Initial price movement (news-inspired or random) triggers short-term indicators
- Trades triggered by that signal set price in motion to trigger medium-term indicators
- Which in turn causes price to move enough to trigger the long-term indicators
- Investor actions become correlated forming a herd effect
- Hong & Stein (HS) Hypothesis
- Explains momentum, underreaction and overreaction
- There are two main groups of traders
- News traders - don’t watch prices - trade on fundamentals
- Momentum traders - technical analysts
- Interactions between these two groups creates positive feedback which in turn creates price momentum
- Investors have intellectual limits which means they can’t focus on all information - hence the focused groups
- Rational levels are set by fundamentals but fundamental traders don’t extract price info from charts
- Momentum traders overshoot levels because they have no way of knowing when the news has fully diffused and understood by all traders
- Fundamentals bring price back in line gradually
Nonrandom Price Motion in the Context of Efficient Markets
- Even if markets are fully efficient the case for TA is not lost
- How systematic price motion and market efficiency can coexist
- Lo & McKinlay - A Non-Random Walk Down Wall Street
- “Predictability is the oil that lubricates the gears of capitalism”
- Grossman & Stiglitz - efficient markets must offer profit opportunities to motivate arbitrage
- There is only one special condition under which market efficiency necessarily implies that price movement must be random and unpredictable
- When all investors have the same attitude towards risk
- An implausible condition
- “Too many test pilots and high steel workers or not enough of them”
- More realistic to assume diverse risk profiles
- Insurance premium examples - I’m going to skip this as Shiller has taught us everything we need to know about it - but the idea is risk can be transferred for a price
- Financial market risk premia:
- Equity market risk premiums - investors provide working capital for businesses and are compensated by receiving a return above the risk-free rate
- Commodity and currency hedge risk transfer premium - speculators take positions to give hedgers (users and producers) the ability to shed price change risk
- Liquidity premium - Investors take positions in less liquid securities with parties who have a short-term need for cash
- Info or price discovery premium for promoting market efficiency - compensation for moving prices to rational levels - arbitrage
- Inefficiencies are ephemeral
- Returns from risk premia are more likely to endure as they represent a payment for a service
- Hedge risk premium and the gains to trend-following commodity futures
- Commodities future markets perform an economic function different from stock/bond markets
- Stock and bond markets provide companies with equity and debt financing
- Futures markets in contrast, protect hedgers from price risk
- Trend followers are exposed to significant risks
- “Most trend-following systems generate unprofitable signals 50-65 percent of the time.” (??? see my footnote)
- The Mount Lucas Management Index of Trend Following Returns (MLM)
- An historical record of the returns that can be earned by an ‘extremely simplistic’ trend-following formula
- Estimates the returns that can be earned by investing in an asset class with no special skill
- MLM suggests that commodity futures markets contain systematic trends that can be exploited with simple TA methods
- Uses a simple MA crossover strategy - using a 12 month MA on 25 commodity markets
- If price is above MA - long, and below - short
- Annualized return and risk measured by the standard deviation in annual returns
Attached Image
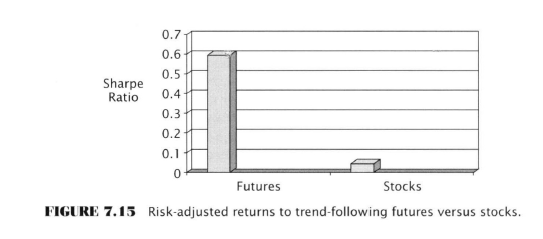
- Since stocks don’t offer a risk-transfer premium, in theory trend-following in stocks should not be as rewarding
- Lars Kestner - data suggests that trend-following in stocks is less rewarding
Attached Image
The way the Fed transfers risk away from investors is not even considered by Aronson though.
Liquidity premium and the gains to counter-trend trading in stocks
- The stock market offers traders a different form of compensation.
- They can earn a return by providing liquidity to highly motivated sellers
- Owners of stock with an urgent need to liquidate need buyers
- Michael Cooper
- Buyers of oversold stocks can earn above-average short-term returns
- Stocks that have negative price momentum on declining trading volume earn excess returns
- Stocks that have declined sharply in past two weeks on declining volume have a systematic tendency to rise over the following week
- Declining volume could be a sign there are insufficient buyers to meet the needs of sellers
“Ultimately it is up to each method of TA to prove that it can [capture a portion of the nonrandom price behaviour].”
- #73
- Aug 11, 2020 12:32pm Aug 11, 2020 12:32pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Part II (Chapter 8: Case Study: Signal Rules for the S&P 500 Index)
I wasn’t sure how much detail to use when summarizing this chapter. Aronson goes into great detail about the setup for his case study. Of course he is duty-bound to do this since otherwise he could incur some criticism at the hands of academic critics who might judge him for a lack of sophistication or mathematical rigour.
However I’m going to leave out most of the material that is specific to his particular experiment and simply focus on what is more generalizable - his descriptions of indicators and rule types.
Some readers might feel I’m doing a disservice, but 


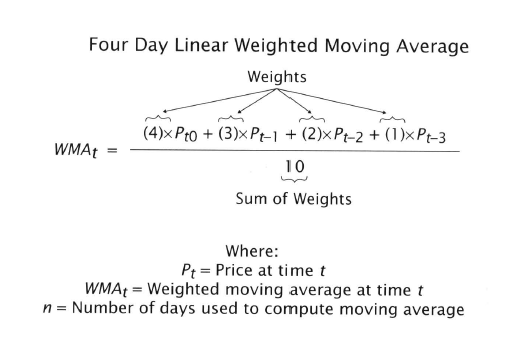
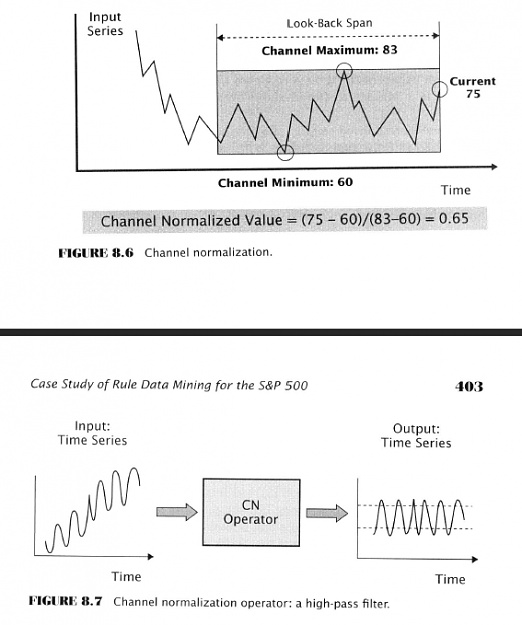
Are you impressed by all these equations yet? Yawn! 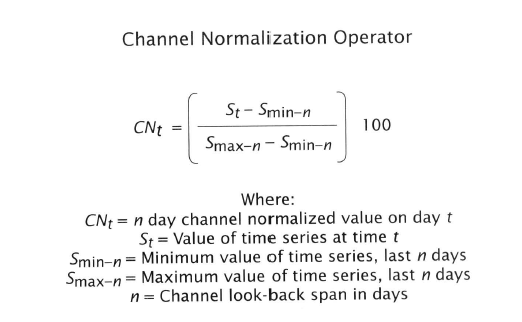
Here Aronson goes into some detail about scripting for the indicator, smoothing, and indicator scripting languages (ISL). I’m going to skip it as beyond the scope of this introductory text and my immediate purpose for the Finance Book Club.
He also goes into the procedures for converting input series from raw time series. I guess this is what he meant by ‘using other data series’ as he used these series to produce his own indicators? Skipped.
Next: Price & Volume Functions
Google Doc (footnotes)
I wasn’t sure how much detail to use when summarizing this chapter. Aronson goes into great detail about the setup for his case study. Of course he is duty-bound to do this since otherwise he could incur some criticism at the hands of academic critics who might judge him for a lack of sophistication or mathematical rigour.
However I’m going to leave out most of the material that is specific to his particular experiment and simply focus on what is more generalizable - his descriptions of indicators and rule types.
Some readers might feel I’m doing a disservice, but
- Otherwise it will take just about forever to get through this book, which, despite its quality, is fairly dry and technical
- If you’re really curious you can just buy (or borrow) the book.
- When you see the final test results you’ll completely understand why the particulars of Aronson’s experiment are not that important.
Data-Mining Bias and Rule Evaluation
- ‘Primary purpose’ of this case study is to illustrate the application of statistical methods that take into account the effect of data-mining bias. Uh-oh. I (and everyone purchasing this book) thought it was about finding and sharing profitable trading rules?!
- Illustrates application of enhanced version of White’s reality check and Masters Monte Carlo Permutation methods
- ‘Secondary purpose’ was to discover trading rules with statistically significant profits. Uh-oh again. This is how you tell bad news to the king. Uh, King, our primary goal wasn’t to discover India and get stinking rich, it was to encounter new experiences, document new customs, and uh...bring glory to the scientific establishment. Yeah, that’s the ticket.
- Avoidance of Data-snooping bias
- Data snooping is using the results of prior rule studies reported by other researchers
- Those studies don’t usually disclose the amount of data mining that led to the discovering of whatever it was that was discovered , so there is no way to take its effects into account and therefore no proper way to evaluate the statistical significance of the discovery
- Martin Zweig’s double 9:1 upside/downside volume rule example
- Long when the daily ratio of upside to downside volume on the NYSE exceeds a threshold value of 9 on 2 instances within a 3month time window
- Note 3 free parameters - 9(the ratio), 3 (mths), 2(instances)
- This rule, tested by Aronson’s students, is significant
- However Zweig doesn’t reveal if he mined these parameters from other tests
- If Aronson included this rule in his list of rules he couldn’t control for data-mining bias
- Hence, Aronson used no rules discussed by other researchers
- But, ever-cautious, Aronson advises this didn’t stop him from being affected by rule studies he might have read in the past
- Analyzed data series
- All rules (6,402) were tested for profitability on the S&P500
- However the “vast majority” used data series other than the S&P500 to generate buy and sell signals (???) When? For What? I’m not sure what Aronson is saying here. These other rules have been used by other researchers/investors/traders in other markets before? I mean, Duh.
- Data series
- Market indices - transportation stocks
- Market breadth (upside/downside volume)
- Indicators combining price and volume (OBV)
- Prices of debt instruments (BAA bonds)
- Interest-rate spreads (10yr treasury - 90 day treasury bills)
- ‘In the spirit of intermarket analysis discussed by Murphy’
- TA Themes
- Trends
- Generate long and short positions based on trend of the data series
- Extremes and transitions
- Generates long and short positions based extreme high or low valuesor as it makes a transition between those
- Divergences
- S&P500 index trends in one direction while a companion data series trends the other way
- Trends
- Analysis methods
- Moving Averages
- Channel Breakouts
- Stochastics (called channel normalization by Aronson)
- Performance Statistic
- Average return over the period (1980-2005) on detrended S&P500 data
- No complex rules were evaluated
- “To keep the scope of the case study manageable” it uses only individual rules
- “Limiting the case study to single rules was detrimental for two reasons”
- Few practitioners rely on single rules to make choices
- Complex rules “exploit informational synergies between individual rules”
- At least one study has shown that using complex rules can produce ‘good performance’ even when the individual rules were unprofitable
- Case study stats
- Population: set of daily returns earned by a rule for signals applied to S&P500 over all possible realizations in the immediate practical future
- Infinite in size
- Pop. param: expected average annualized return in the IPF
- Sample: daily returns earned by a rule on detrended S&P500 index prices from Nov. 1 1980 to July 1 2005
- Sample stat /test stat: Average annualized rule return on the same data
- Null Hypothesis: all 6402 rules are without predictive power
- 2 different ones - one for WRC and one for MCP
- Alt hypo: At least one rule has predictive power (one hypo for WRC/MCP)
- Stat Significance Level: 5% threshold for rejection (5% chance of rejecting the null hypo when it was true)
- Rules - transforming data series into market positions
Attached Image
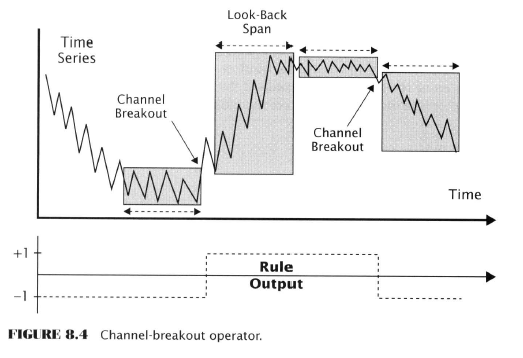
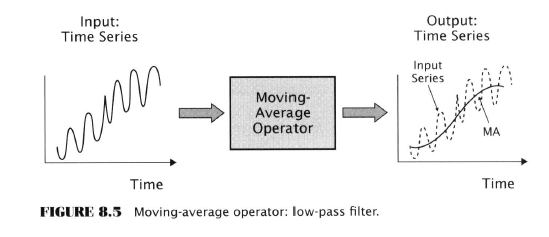
- Time-series operators
- Channel breakout operator (CBO)
- Identifies trends
- “See past the underlying noise in a time series, find the current direction of the series.”
- Lower and upper boundaries are defined by the min. and max. prices over n-periods
- ‘Extreme simplicity’ but as effective as ‘more complex methods’
- Dynamic range - may reduce false signals caused by increase in volatility instead of actual trend changes
- Channel breakout operator (CBO)
Attached Image
- Moving averages
- Identifies trends/smoothing
- Among most widely used time-series operators
- Filters out high frequency (short-period) fluctuations and lets through long period components
- Smoothes by averaging time series values
- SMA lag = look-back span minus one period
- Ehlers digital filters mentioned
- LWMA, lag = (N-1)/3A
Attached Image
Attached Image
Attached Image
Attached Image
Are you impressed by all these equations yet? Yawn!
- Channel normalization (stochastics) (CN)
- Eliminates the trend (detrends)
- Detrends by measuring the current position within a moving channel
- Channels are measured by min/max prices as with the CBO
- Scaled to a 0-100 range
- Functions as a high-pass filter, in contrast to an MA
- Heiby - measured divergences by comparing the channel-normalized value of a market-breadth indicator with the S&P500
- Heiby - divergence occurred when one series was in the upper quartile of its 50 day range (CN>74) while the other series was in the lower quartile (CN<26).
- In the 1970s - George Lane described a ‘virtually identical operator’ and named it stochastic and the name stuck. However it’s inaccurate, so Aronson calls it (CN operator)
Attached Image
Attached Image (click to enlarge)
Here Aronson goes into some detail about scripting for the indicator, smoothing, and indicator scripting languages (ISL). I’m going to skip it as beyond the scope of this introductory text and my immediate purpose for the Finance Book Club.
He also goes into the procedures for converting input series from raw time series. I guess this is what he meant by ‘using other data series’ as he used these series to produce his own indicators? Skipped.
Next: Price & Volume Functions
Google Doc (footnotes)
- #74
- Aug 12, 2020 5:03pm Aug 12, 2020 5:03pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 8: Case Study: Signal Rules for the S&P 500 Index - part 2
Indicators: Price & Volume Functions 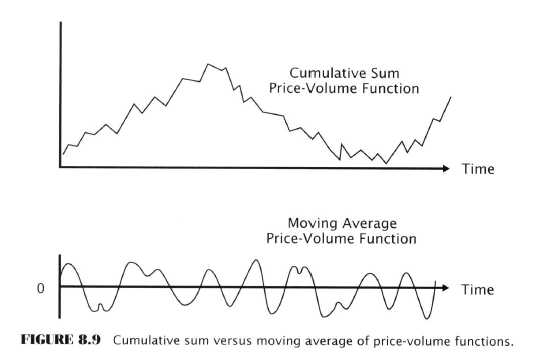







Indicators: Price & Volume Functions
- Fifteen indicators combined price and volume information
- “A number” of studies show that trading volume contains useful info on its own and when used with price
- On-balance volume
- Accumulation-distribution volume
- Money flow
- Negative and Positive Volume
- The price-volume functions were used to create two types of indicators
- Cumulative sums
- The algebraic sum of all prior daily values of the price-volume function
- Nonstationary time series
- Moving averages
- A moving average of a price-volume function will be a stationary series
- It will not display trends
- Cumulative sums
Attached Image
- Cumulative On-Balance volume
- Granville, Woods, Vignolia
- Cumulative sum of signed total market volume
- Algebraic sign of the volume for any given day is determined by the sign of the change in the market index for the period/interval
- If price rose on volume that day’s entire NYSE volume was assigned a positive value and added to the series, cumulatively, reverse for when price fell for the day
Attached Image
- Moving averages of On-Balance Volume (OBV)
- OBV10 and OBV30
- Cumulative Accumulation-Distribution Volume (CADV)
- Marc Chaiken
- Similar to Intra-day intensity (Bostian) & Variable AD (Williams)
- Minor price changes are not treated the same as large
- Takes the difference between closing price and midpoint of the daily range and divides the difference by the size of the range
Attached Image
- Cumulative Money Flow (CMF)
- Similar to CADV but the product of volume and range factor is multiplied by the price level in dollars of the S&P500
- Measures the monetary value of the volume
- Price level is an average of the daily, high, low, close prices
Attached Image
- Moving averages of money flow
- MF10 & MF30
- Cumulative Negative Volume Index (CNV)
- CNV is an accumulation of price changes on days of lower trading volume
- Algebraic sum of daily percentage changes in a stock market index on days when volume is less than the prior day
- When volume is greater or equal, the CNV remains unchanged
- Attributed to Fosback or Dysart
- Based on the conjecture that “trading by unsophisticated investors occurs predominately(sic) on days of exuberantly rising volume, whereas informed buying and selling (smart money) occurs during quieter periods of declining volume”
Attached Image
- Moving averages of Negative Volume Index
- NV10 & NV30
- Cumulative Positve Volume Index (CPV)
- Opposite of CNV
Attached Image
- MA of PV
- PV10, & PV30
Market-Breadth Indicators
- Market-breadth refers to the spread or difference between the number of stocks advance and the number declining on a given day, week or other defined time interval
- Studied by Harlow
- In this study breadth is defined as the daily advance-decline ratio
- The difference between a day’s advancing and declining issues divided by the total number of issues traded
- Cumulative Advance-Decline Ratio (CADR)
- Cumulative sum of the daily advance-decline ratio
Attached Image
- MA of Advance-Decline ratio
- MA(ADR10), MA(ADR30)
- Cumulative Net Volume Ratio (CNVR)
- Based on the difference between daily upside and downside volume
- Upside volume is the total number of shares traded in stocks that closed up for the day, inverse for Downside
- Lyman M Lowry (1938)
Attached Image
- MA of NVR
- 10 and 30 as usual
- Cumulative New Highs-Lows Ratio (CHLR)
- Based on a stock’s current price relative to its maximum and minimum price over the preceding year
- Takes a longer view
- Cumulative sum of the daily new highs-new lows ratio, a quantity that can assume positive or negative values
- Defined as the difference between the number of stocks making new 52 wk highs on the day and the number of stocks making new 52 wk highs on the day and number of stocks making new 52 wk lows on the same day divided by the total number of issues traded that day.
- #75
- Aug 13, 2020 9:58pm Aug 13, 2020 9:58pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 8: Case Study: Signal Rules for the S&P 500 Index - part 3
Price-of-Debt Instruments 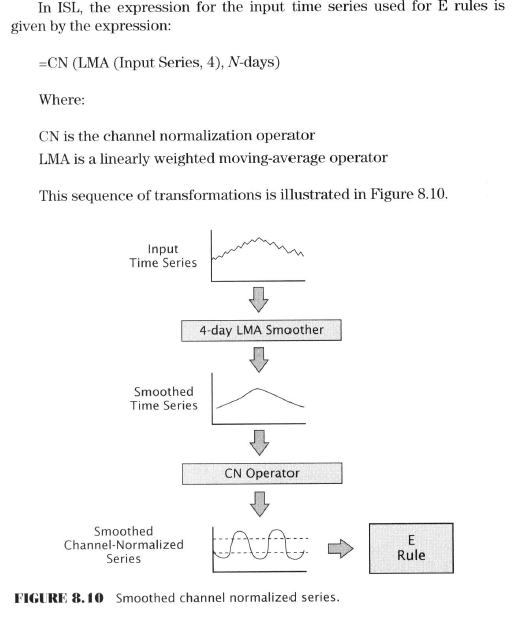
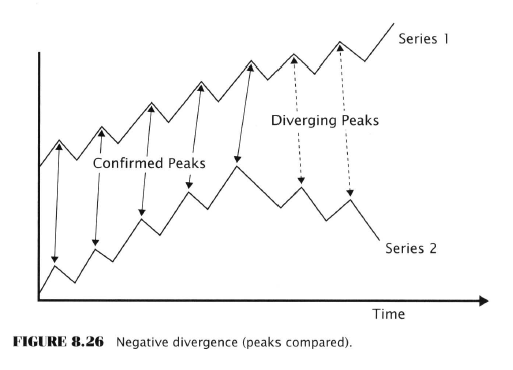
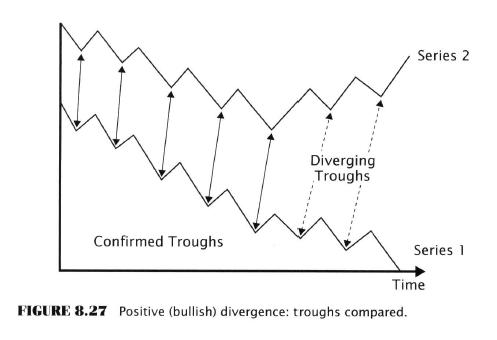
Next: An objective measure of divergence
Price-of-Debt Instruments
- Typically, interest rates and stock prices move inversely
- By taking the reciprocal (1/interest rate) of the int. rate they can be turned into price-like time series that are generally correlated with stock prices
- Scaled by a factor like 100, so a rate of 6.05 becomes 1/6.05 x100 = 15.38(sic?) (??? - no Aronson, it’s 16.52? Am I missing something?)
- Tested on 3mth t-bills, 10y t-bonds, AAA corp. bonds and BAA corp. bonds
Interest-Rate-Spread Indicators
- An interest rate spread is the difference between two comparable interest rates
- The study spreads:
- Duration spread
- Aka slope of the yield curve
- Difference between yields on debt instruments with the same credit quality but different time to maturities
- Study used: 10y t-notes minus 3mth yields
- Quality spread
- Measures the difference between yields of different credit qualities
- Study used Moody’s long-term AAA bond series and BAA, lower-rated corp. debt
- AAA - BAA
- When rates on lower quality debt are falling faster than on higher quality debt, it’s interpreted as investors being more willing to take on additional risk to earn higher yields on lower quality
- Higher quality spreads = more risk tolerance; stocks should follow suit
- Duration spread
https://lh4.googleusercontent.com/9K...9mUB9Wr2ImfNkG
https://lh6.googleusercontent.com/J-...8PVfi1w-SO7-DN
https://lh3.googleusercontent.com/Vi...PfBxtoiHRCmawp
https://lh3.googleusercontent.com/fr...EGmuFSq6q-HpHo
https://lh6.googleusercontent.com/uS...CX-iT1lt2htNiQ
https://lh5.googleusercontent.com/SK...LFFZvhblHeyg8O
https://lh4.googleusercontent.com/07...HRQmw64-_wUePo
https://lh5.googleusercontent.com/Hk..._Njf2lqGJh2Zy1
The Rules
- Trend Rules
- TA foundational principle - prices and yields move in trends that can be identified in sufficient time to generate profits
- Moving Averages
- Moving Average Bands
- Channel Breakout
- Alexander Filters (zigzag) - Kaufman
- Various lookback periods, 3,5,8,12,18,27,41,61, 91, 137, 205 days
- Upward trend -> +1 (buy)
- Downward trend -> -1 (sell) (see diagrams above)
- Extreme Values and Transitions
- Based on the notion that time series convey info at extremes or as it transitions between extremes
- Input series for these rules were made stationary by using the CN operator
- 4 day LMA smoothing
Attached Image
- A wide variety of displacement-threshold settings tested
- For example 12 rule types x 39 input series x 2 displacements x 3 CN lookback spans = 2,808 E-type rules
- Divergence rules
- Premise is that certain pairs move up or down together and when they fail to do so it conveys information
Attached Image
- Coherence is the fundamental idea
- When two series are coherent their common trend is strong and expected to continue
- When incoherent the trend is in question
- Stable lead-lag relationship
Attached Image
- Subjective divergence analysis
- Compares peaks and troughs of two time series under consideration
- Bearish divergence occurs if one series continues higher making new successive peaks while the other makes lower peaks
- Bullish divergence occurs if one series registers successively lower troughs while the second series forms troughs at higher levels
- Subjective - not testable
- Peaks and troughs may not form exactly coincident so it’s unclear which peaks and troughs should be compared
- How long should divergence last to be considered?
- How much upward or downward price movement is needed to establish a peak/trough?
Attached Image
Attached Image
Next: An objective measure of divergence
- #76
- Aug 16, 2020 1:57pm Aug 16, 2020 1:57pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 8 - part 4 of 4 
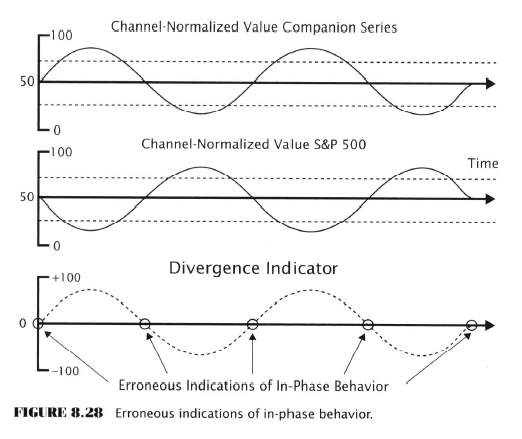
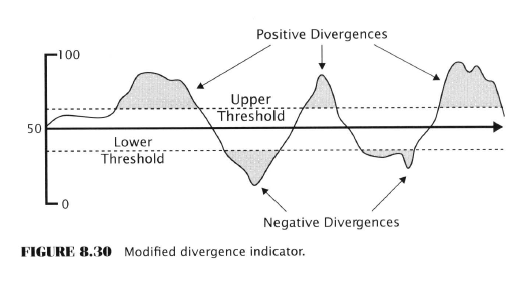
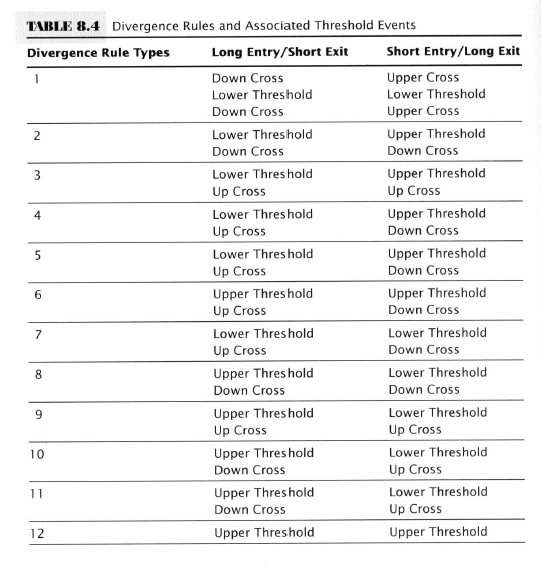
Next - case study results and the future of TA!
- An objective measure of divergence
- Objective Divergence Analysis
- Method objectifies peak and trough comparisons - Kaufman
- Uses linear regression or Alexander filters to estimate slopes in the two series being compared
- No performance statistics available
- Heiby - Stock Market Profits Through Dynamic Synthesis
- Detrended series with channel normalization
- Defined divergence if one series had a CN value of 75+ while the other had a value of 25-
- Divergence = difference in channel-normalized values
- Indicator range from -100 to +100
Attached Image
- Limitations of the proposed divergence indicator
- Measures the degree to which two time series have similar positions within their respective channels
- If two time series are negatively correlated, a reading of zero will occur, this doesn’t, as it usually does, show they are trending together, it’s actually the opposite
Attached Image
- This problem could have been avoided with cointegration - Engle & Granger 1987
- Uses regression analysis to determine if a linear relationship exists between two time series
- Easily accommodates the case where a series pair are negatively correlated (180 degrees out of phase)
- An additional advantage is it applies a statistical test to determine if two series have related trends (they are cointegrated)
- The indicator showing divergence between two cointegrated series is the error-correction model
- Error is expected to correct over time, the departure from the normal linear relationship will decrease
- Used in pairs trading - one is bought, the other is sold then no matter how the difference is corrected, the trade is overall profitable
- Fosback index - uses the measurement from the error-correcting model to predict the S&P500
- Exploits the cointegration of interest rates and mutual fund cash levels
- When mutual fund managers are excessively pessimistic about the stock market they hold cash reserves higher than that predicted by interest rates
- Excessive optimism shows the opposite
- Provides a purer vision of fund manager sentiment, uncontaminated by interest rates
- Divergence Rule Types
- Upper and lower threshold applied to the modified divergence indicator to generate signals
- Bullish divergence when divergence indi was above upper threshold
- Bearish when below lower threshold
- Long SP500 when above upper
- Short SP500 when below lower
- Plus inverse versions of these rules just to be sure
Attached Image
Attached Image
Next - case study results and the future of TA!
- #77
- Aug 17, 2020 1:32pm Aug 17, 2020 1:32pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Chapter 9 - Case Study Results and the Future of TA
This is it! Time for the big reveal!
Once again Aronson tries to soften the blow by telling us the purpose of the study was to demonstrate statistical inference methods suitable for evaluating data-mining rules. Sure, sure. 
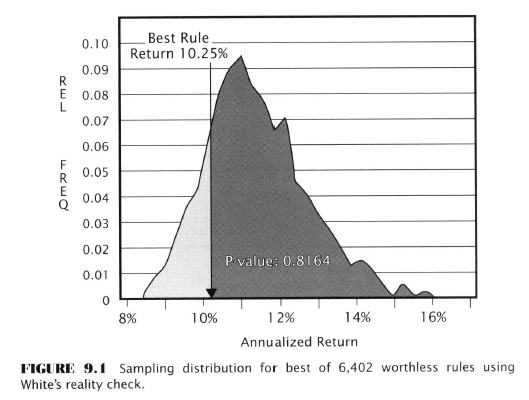
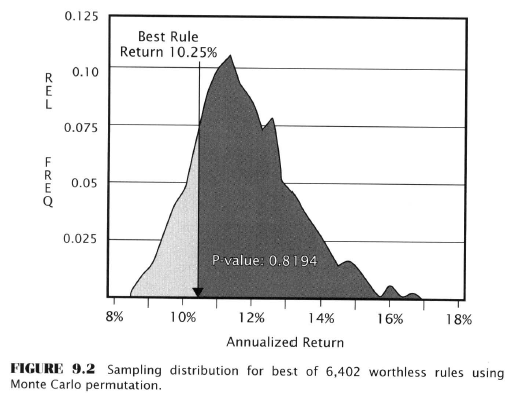

The Future of Technical Analysis
This is it! Time for the big reveal!
Once again Aronson tries to soften the blow by telling us the purpose of the study was to demonstrate statistical inference methods suitable for evaluating data-mining rules. Sure, sure.
- The case study ‘resoundingly demonstrated the importance of using significance tests to cope with data-mining bias’ Yes, of course.
- and then, without further ado, drumroll please....
Attached Image
- No rules with statistically significant returns were found.
- I will say it again. Out of 6,402 rules, and with all the fancy schmancy mathy wathy trickses used to ensure no bias entered the study, “none of the 6,402 rules had a back-tested mean return that was high enough to reject the null hypothesis at a significance level of 0.05."
- In other words, the evidence must presume that NONE of the rules had predictive power.
Just let this sink in for a second. After 9 chapters of dense slogging through academic-ese and with the aid of all the modern statistical and mathematical expertise available to a modern economist (ca. 2007 admittedly) at the end of it all Aronson comes up completely empty-handed with nothing to show for it!
“Oh I know what I can do to salvage this debacle. I’ll write a book.”
Good one, Aronson! Excellent joke. You had us going there for over 441 pages (so far)!
Dear reader, you can imagine how pissed off and disillusioned I was on first reading this admission of complete failure. Does that mean we have wasted our time? Well, no, as it turns out we have learned something (maybe a few things) even more valuable than a trading rule that might work for a few months and then mysteriously stop working. But let me save that for the end.
- The rule with the best performance generated a mean annualized return of 10.25 percent
- P-value of 0.8164 is far above 0.05 (smaller is better, remember)
- This is well within the range of ordinary sampling variability
- In fact it is below the sampling distribution’s central value of 11 percent
- “Quite disappointing!” says Aronson
Attached Image
Attached Image
- Returns in excess of 15 percent would have been significant at 0.05
- 17 percent would have been ‘highly significant’ (p-value <.001)
- “Had I used an ordinary significance test, which pays no attention to data-mining bias, the mean return of the best rule would have appeared to be highly significant (p-value of 0.0005)
- With a conventional test, 320 rules would have appeared significant at 0.05 level
- In reality, this would have produced ‘nothing but fool’s gold’
- Aronson has wasted
a lotsome time, sure but at least he didn’t blow an account on a worthless philosophy. How many retail traders can say that? Not me!
Critique (Aronson’s) of the Case Study
Positive Attributes
- Use of benchmarks in rule evaluation - absolute levels of performance are uninformative
- Controlled for market trends (detrended data)
- Controlled for look-ahead bias
- Controlled for data-mining bias - most rule studies don’t says Aronson
- Controlled for data-snooping bias - the use of prior research that may not have controlled for other biases
Negative attributes
- Complex rules were not considered
- A severe defect
- Few TA practitioners restrict themselves to single rules
- However few practitioners can handle complex rules either
- Ashby’s Law of Requisite Variety - a problem and its solution must have similar degrees of complexity
- Since the markets are a difficult nut to crack, Aronson reasons, the solution must be equally complex
- Aronson cites another study that found complex rules produced ‘statistically significant profits’ although they did not work on the S&P500, or the DJIA, only the NASDAQ and Russell 2000.
- Simple rules were used in the overconfident belief that at least a few would work and to keep the scope manageable
- Only long/short rules were considered
- Rests on the unlikely assumption that the market is in a perpetual state of inefficiency and continually presents profit opportunities
- More selective rules might be more reasonable
- Rules were limited to S&P500 trading
Case Study Extensions
- Application to less seasoned stock indexes
- Newer markets may be more predictable but they have less data to study
- Improved indicator and rule specification
- The more effectively an indicator quantifies market behaviour the higher the rule’s profit potential You sure about that? Cite your sources, Doctor!
- Maybe trends, extremes and divergences were dead ends
- Maybe cointegration, Ehlers Fisher transform are the ticket - no evidence yet
- Consideration of complex rules
- Which rules?
- How to combine them?
- Linear combination - equal weights to each constituent
Attached Image
- Black box formulas (nonlinear) - like neural networks
- Continuous variables
- Diffusion indicators
- Machine-Induced Nonlinear Combinations - oh my!
- Neural nets
- Decision trees, etc - I think we went over this already
- Notes about overfitting, training, testing, validating data sets
- The concept of complexity search
- Adding more complexity allows us to overfit, essentially
Attached Image
The Future of Technical Analysis
- The future depends on the path practitioners take
- Intuitive, anecdotal
- Scientific - evidence-based, confined to testable methods
- “Technical analysis will be marginalized to the extent it does not modernize”
- History of science shows that few practitioners who are committed to a paradigm ever abandon it, even after it’s been discredited
- Beliefs are resilient
- There will always be some audience for soothsayers and diviners because of a psychological need to reduce anxiety provoked by the uncertainty of the future
- Armstrong - the Seer-Sucker Theory: The Value of Experts in Forecasting
- People pay heavily for experts even though they perform poorly
- What they are buying is an illusory reduction of risk
- Alfred Cowles - studying Hamilton, editor of the WSJ found 50% of his forecasts were false
- Hulbert’s financial digest
- Wall St. seems to have had enough of traditional TA (ca. 2005 - we should know by now if it was a trend)
- Evidence-Based Technical Analysis
- Limited by ability to conduct controlled trials - same as archaeology, paleontology, geology
- Felsen - the human/computer partnership (in action)
- Computers go fast, but humans are inventive
- Curse of dimensionality - Bellman
- As the number of indicators making up a multidimensional space is increased, where each indicator is represented by a dimension, the observations become less dense at an exponential rate
- Data-mining requires an amount of data density
- Statistical models outperform intuition - Paul Meehl
- Sawyer supports this - humans overvalue nuanced information from interviews
- Camerer - mathematical models more accurate than subjective judgments
- People do poorly when trying to combine a multitude of variables to make predictions or judgments - Goldberg
- Hastie & Dawes - experts making subjective judgments based on a small number (3-5) of inputs
- Experts use linear models of inputs
- Few judges use nonlinear thinking to combine inputs even if they are under the impression they do so
- Experts don’t understand how they arrive at judgments, a problem most pronounced by highly experienced experts - results in inconsistency
- Judges often don’t agree on the same data set
- Irrelevant information increases confidence but not accuracy
- Few judges are demonstrably superior
- Tetlock - fox vs hedgehog
- Computers are the future, etc. etc.
Next- what have we really learned, really?
- #78
- Aug 17, 2020 3:36pm Aug 17, 2020 3:36pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
If you've read this far you might be wondering where this is going. Are we making any progress? This thread's already 4 whole pages!
Well, let's look at what we've reviewed so far.
Well, let's look at what we've reviewed so far.
- Mark Tier - some general tips, without which failure is probably assured, and evidence that at least some (possibly just lucky?) traders make money
- Robert Shiller - some jargon and finance concepts that we should really know to avoid appearing stupid even if they might not help us become traders. A view from the academic side of markets.
- Nassim Taleb - randomness is everywhere and it's out to get us pattern-detecting primates! Beware!
- David Aronson - another academic who made at least some attempt to rein in the chaos of subjective technical analysis, and wasn't wholly successful. Randomness strikes again?
It might seem like Aronson led us down the garden path but what we learned wasn’t completely wasted. And it could be of vital use later on.- We learned some sciencing.
- We learned some statistical concepts like sampling distributions and p-values.
- We learned that even if you’re fairly smart, coming up with reliable TA rules is hard. Really hard.
- We learned that lots of folks think their TA rules work and they probably don’t because there are so many pitfalls, both mathematical and psychological. I bet most of those people hang in as long as they can, lose most of their money to their brokers in the long run and then give up because
- It’s too hard
- It’s rigged (never mind that a rigged game is the easiest to win once you know how)
Does this mean TA doesn’t work?
We haven’t proven it yet, but for me, it means we need to be humbler in our perceived ability to forecast future prices.
Think about it - I know you're really smart, but if a bunch of smart people like Aronson, Mandelbrot, Shannon, even Elder, Ehlers and the rest of the TA crew have tackled the problem of predicting market moves, and didn’t become billionaires (that we know about) and also just about every modern expert cannot do it (see my notes on FXStreet, ScorpionFX, Growth Aces, Patrick Munnelly, NoNonsenseFX, Huddleston, et al, for ex.) what chance do we have?
My opinion (which may change) is that it’s not hopeless, but I think we should move away from the ‘traditional’ technical analysis of Elliott/Gann/Fibonacci/periodic indicators and look at more exotic ideas like cyclical analysis (Hurst) and methods that don’t forecast. We haven’t even begun to delve into fundamental analysis yet, and we’ve barely scratched the surface of quantitative methods. So, there’s lots more to explore before we reach any ultimate conclusions.
Attached Image (click to enlarge) 
-Before we abandon all traditional TA methods though let’s check out Al Brooks (modern candlestick patterns) but before that let’s read Reminiscences, which is not about TA but about good old fashioned trading ‘horse sense’ which might be the most important type of training of all
3
- #80
- Aug 17, 2020 4:06pm Aug 17, 2020 4:06pm
- Joined Jul 2016 | Status: Trader | 2,534 Posts
Oh, and I just noticed that the 'Predicting Price Action' book has more votes in the poll than any other un-reviewed book so I should review it first.
Luckily, it's really easy.
This is just a pamphlet, about 25 pages long (nice!) and it basically makes only one hypothesis.
The Forex market shows evidence of price momentum.
The authors are Scott Owens and Omer Lizotte, two guys who started a business called FXEngines, which is now sadly, out of business. I guess they were best known for producing news-trading robots that didn't work very well, either because news-trading is hard, too hard for ordinary robots, or because they were using another broker's (FXCM) back-end for execution and it was slow. Maybe a bit of A&B.
Anyway O&L ask, "How likely is a price move continuation given varying conditions"? and then they made some tables like this one
"When price moves 10 pips in either direction what is the probability it will continue?"
What's interesting is that (according to O&L) it is very likely to continue rather than to retrace given enough time. What's also interesting, is that after a certain amount of time, waiting longer for price to continue is not of much benefit.
How the study was done
Luckily, it's really easy.
This is just a pamphlet, about 25 pages long (nice!) and it basically makes only one hypothesis.
The Forex market shows evidence of price momentum.
The authors are Scott Owens and Omer Lizotte, two guys who started a business called FXEngines, which is now sadly, out of business. I guess they were best known for producing news-trading robots that didn't work very well, either because news-trading is hard, too hard for ordinary robots, or because they were using another broker's (FXCM) back-end for execution and it was slow. Maybe a bit of A&B.
Anyway O&L ask, "How likely is a price move continuation given varying conditions"? and then they made some tables like this one
Attached Image (click to enlarge)
What's interesting is that (according to O&L) it is very likely to continue rather than to retrace given enough time. What's also interesting, is that after a certain amount of time, waiting longer for price to continue is not of much benefit.
How the study was done
- data is from tick data Jan. 2000-May 2004, with daily data through to Oct 2004
- They took 5,000 observations for each interval (sample sizes, remember?)
- They studied four common pairs - Fibre, Cable, Yen, Swissy
- They observed the pair over 24 intervals
- They used a stop of 20 pips for all simulated trades
- They ignored spreads
Overall their little experiment (which they caution does not meet any standard of rigour or scientific accuracy and may be subject to seasonality) shows that momentum (trends) continue with high reliability especially if our profit goals are modest. I think this is the kind of experiment that bears repeating.
This study convinced me that trading with fixed exits is superior to using trailing. It's also a good basis for trying out different exit strategies that can use a hybrid short-term/long-term move approach. This type of focused research is unfortunately fairly rare, and is rarely done by retail traders, though they should.
FXEngines also used to offer a backtester which would have been interesting to check out, but sadly I don't think you can get it anymore.
3